
A Chinese input method which support quanpin, shuangpin, wubi and cangjie.
目录
- 1. pyim 使用说明
- 1.1. 截图
- 1.2. 简介
- 1.3. 背景
- 1.4. 目标
- 1.5. 特点
- 1.6. 安装
- 1.7. 配置
- 1.8. 使用
- 1.9. 捐赠
- 1.10. Tips
- 1.10.1. 如何将个人词条导出到一个文件
- 1.10.2. pyim 出现错误时,如何开启 debug 模式
- 1.10.3. 选词框弹出位置不合理或者选词框内容显示不全
- 1.10.4. 如何查看 pyim 文档。
- 1.10.5. 将光标处的拼音或者五笔字符串转换为中文 (与 vimim 的 “点石成金” 功能类似)
- 1.10.6. 如何添加自定义拼音词库
- 1.10.7. 如何手动安装和管理词库
- 1.10.8. Emacs 启动时加载 pyim 词库
- 1.10.9. 将汉字字符串转换为拼音字符串
- 1.10.10. 中文分词
- 1.10.11. 获取光标处的中文词条
- 1.10.12. 让 `forward-word' 和 `back-backward’ 在中文环境下正常工作
- 1.10.13. 为 isearch 相关命令添加拼音搜索支持
- 2. 核心代码
- 2.1. require + defcustom + defvar
- 2.2. 将变量转换为 local 变量
- 2.3. "汉字 -> 拼音" 以及 "拼音 -> 汉字" 的转换函数
- 2.4. 输入法启动和重启
- 2.5. 处理词库文件
- 2.6. 生成 `pyim-entered-code' 并插入 `pyim-dagger-str'
- 2.7. 处理拼音 code 字符串 `pyim-entered-code'
- 2.8. 处理当前需要插入 buffer 的 dagger 字符串: `pyim-dagger-str'
- 2.9. 显示和选择备选词条
- 2.10. 处理标点符号
- 2.11. 处理特殊功能触发字符(单字符快捷键)
- 2.12. 与拼音输入相关的用户命令
- 2.13. 让 forward/backward 支持中文
- 2.14. 简单的中文分词功能
- 2.15. 汉字到拼音的转换工具
- 2.16. pyim 词库管理工具
- 2.17. pyim 探针程序
1 pyim 使用说明
1.1 截图
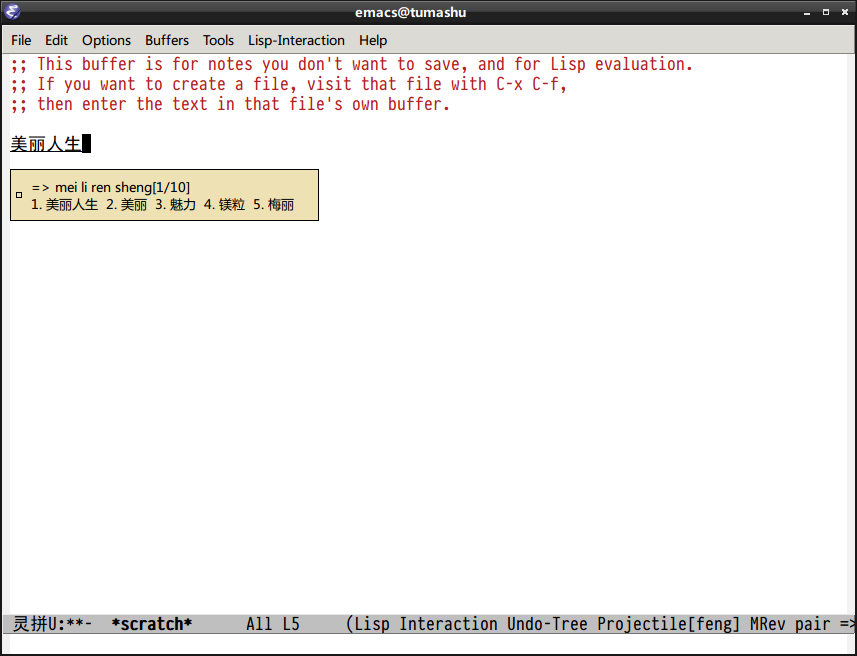
1.2 简介
pyim 是 Emacs 环境下的一个中文输入法,最初它只支持全拼输入,所以当时 "pyim" 代表 "Chinese Pinyin Input Method" 的意思,后来根据同学的提议,添加了五笔的支持,再叫 “拼音输入法” 就不太合适了,所以你现在可以将它理解为 “PengYou input method”: 平时像朋友一样帮助你,偶尔也像朋友一样犯二 。。。
1.3 背景
pyim 的代码源自 emacs-eim。
emacs-eim 是 Emacs 环境下的一个中文输入法框架, 支持拼音,五笔,仓颉以及二笔等多种输入法,但遗憾的是,2008 年之后它就停止了开发,我认为主要原因是外部中文输入法快速发展。
虽然外部输入法功能强大,但不能和 Emacs 默契的配合,这一点极大的损害了 Emacs 那种行云流水 的感觉。而本人在使用(或者叫折腾) emacs-eim 的过程中发现:
- 当 emacs-eim 词库词条超过 100 万时,选词频率大大降低,中文体验增强。
- 随着使用时间的延长,emacs-eim 会越来越好用(个人词库的积累)。
于是我 fork 了 emacs-eim 输入法的部分代码, 创建了一个项目:pyim。
1.4 目标
pyim 的目标是:尽最大的努力成为一个好用的 Emacs 中文输入法,具体可表现为三个方面:
- Fallback: 当外部输入法不能使用时,比如在 console 或者 cygwin 环境下,尽最大可能让 Emacs 用户不必为输入中文而烦恼。
- Integration: 尽最大可能减少输入法切换频率,让中文输入不影响 Emacs 的体验。
- Exchange: 尽最大可能简化 pyim 使用其他优秀输入法的词库的难度和复杂度。
1.5 特点
- pyim 支持全拼,双拼,五笔和仓颉,其中对全拼的支持最好。
- pyim 通过添加词库的方式优化输入法。
- pyim 使用文本词库格式,方便处理。
1.6 安装
- 配置 melpa 源,参考:http://melpa.org/#/getting-started
- M-x package-install RET pyim RET
在 Emacs 配置文件中(比如: ~/.emacs)添加如下代码:
(require 'pyim) (require 'pyim-basedict) ; 拼音词库设置,五笔用户 *不需要* 此行设置 (pyim-basedict-enable) ; 拼音词库,五笔用户 *不需要* 此行设置 (setq default-input-method "pyim")
1.7 配置
1.7.1 配置实例
对 pyim 感兴趣的同学,可以看看本人的 pyim 配置(总是适用于最新版的 pyim):
(use-package pyim
:ensure nil
:config
;; 激活 basedict 拼音词库
(use-package pyim-basedict
:ensure nil
:config (pyim-basedict-enable))
;; 五笔用户使用 wbdict 词库
;; (use-package pyim-wbdict
;; :ensure nil
;; :config (pyim-wbdict-gbk-enable))
(setq default-input-method "pyim")
;; 我使用全拼
(setq pyim-default-scheme 'quanpin)
;; 设置 pyim 探针设置,这是 pyim 高级功能设置,可以实现 *无痛* 中英文切换 :-)
;; 我自己使用的中英文动态切换规则是:
;; 1. 光标只有在注释里面时,才可以输入中文。
;; 2. 光标前是汉字字符时,才能输入中文。
;; 3. 使用 M-j 快捷键,强制将光标前的拼音字符串转换为中文。
(setq-default pyim-english-input-switch-functions
'(pyim-probe-dynamic-english
pyim-probe-isearch-mode
pyim-probe-program-mode
pyim-probe-org-structure-template))
(setq-default pyim-punctuation-half-width-functions
'(pyim-probe-punctuation-line-beginning
pyim-probe-punctuation-after-punctuation))
;; 开启拼音搜索功能
(pyim-isearch-mode 1)
;; 使用 pupup-el 来绘制选词框
(setq pyim-page-tooltip 'popup)
;; 选词框显示5个候选词
(setq pyim-page-length 5)
;; 让 Emacs 启动时自动加载 pyim 词库
(add-hook 'emacs-startup-hook
#'(lambda () (pyim-restart-1 t)))
:bind
(("M-j" . pyim-convert-code-at-point) ;与 pyim-probe-dynamic-english 配合
("C-;" . pyim-delete-word-from-personal-buffer)))
1.7.2 添加词库文件
pyim 当前的默认的拼音词库是 pyim-basedict, 这个词库的词条量 8 万左右,是一个非常小的拼音词库,词条的来源有两个:
- libpinyin 项目的内置词库
- pyim 用户贡献的个人词库
如果 pyim-basedict 不能满足需求,用户可以使用其他方式为 pyim 添加拼音词库,具体方式请参考 1.10.6 小结。
1.7.3 激活 pyim
(setq default-input-method "pyim") (global-set-key (kbd "C-\\") 'toggle-input-method)
1.8 使用
1.8.1 常用快捷键
| 输入法快捷键 | 功能 |
|---|---|
| C-n 或 M-n 或 + | 向下翻页 |
| C-p 或 M-p 或 - | 向上翻页 |
| C-f | 选择下一个备选词 |
| C-b | 选择上一个备选词 |
| SPC | 确定输入 |
| RET 或 C-m | 字母上屏 |
| C-c | 取消输入 |
| C-g | 取消输入并保留已输入的中文 |
| TAB | 模糊音调整 |
| DEL 或 BACKSPACE | 删除最后一个字符 |
| C-DEL 或 C-BACKSPACE | 删除最后一个拼音 |
| M-DEL 或 M-BACKSPACE | 删除最后一个拼音 |
1.8.2 使用双拼模式
pyim 支持双拼输入模式,用户可以通过变量 `pyim-default-scheme' 来设定:
(setq pyim-default-scheme 'pyim-shuangpin)
注意:
- pyim 支持微软双拼(microsoft-shuangpin)和小鹤双拼(xiaohe-shuangpin)。
- 用户可以使用变量 `pyim-schemes' 添加自定义双拼方案。
- 用户可能需要重新设置 `pyim-translate-trigger-char'。
1.8.3 使用五笔输入
pyim 支持五笔输入模式,用户可以通过变量 `pyim-default-scheme' 来设定:
(setq pyim-default-scheme 'wubi)
在使用五笔输入法之前,请用 pyim-dicts-manager 添加一个五笔词库,词库的格式类似:
# ;;; -*- coding: utf-8-unix -*- .aaaa 工 .aad 式 .aadk 匿 .aadn 慝 葚 .aadw 萁 .aafd 甙 .aaff 苷 .aaht 芽 .aak 戒
最简单的方式是从 melpa 中安装 pyim-wbdict 包,然后根据它的 README 来配置。
1.8.4 使用仓颉输入法
pyim 支持仓颉输入法,用户可以通过变量 `pyim-default-scheme' 来设定:
(setq pyim-default-scheme 'cangjie)
在使用仓颉输入法之前,请用 pyim-dicts-manager 添加一个仓颉词库,词库的格式类似:
# ;;; -*- coding: utf-8-unix -*- @a 日 @a 曰 @aa 昌 @aa 昍 @aaa 晶 @aaa 晿 @aaah 曑
如果用户使用仓颉第五代,最简单的方式是从 melpa 中安装 pyim-cangjie5dict 包,然后根据它的 README 来配置。 pyim 支持其它版本的仓颉,但需要用户自己创建词库文件。
用户可以使用命令:`pyim-search-word-code' 来查询当前选择词条的仓颉编码
1.8.5 让选词框跟随光标
用户可以通过下面的设置让 pyim 在光标处显示一个选词框:
使用 popup 包来绘制选词框 (emacs overlay 机制)
(setq pyim-page-tooltip 'popup)
使用 pos-tip 包来绘制选词框(emacs tooltip 机制)
(setq pyim-page-tooltip 'pos-tip)
注:Linux 平台下,emacs 可以使用 GTK 来绘制选词框:
(setq pyim-page-tooltip 'pos-tip) (setq x-gtk-use-system-tooltips t)
GTK 选词框的字体设置可以参考:GTK resources 。
1.8.6 调整 tooltip 选词框的显示样式
pyim 的 tooltip 选词框默认使用双行显示的样式,在一些特殊的情况下(比如:popup 显示的菜单错位),用户可以使用单行显示 的样式:
(setq pyim-page-style 'one-line)
注:用户可以添加函数 pyim-page-style-STYLENAME-style 来定义自己的选词框格式。
1.8.7 设置模糊音
可以通过设置 `pyim-fuzzy-pinyin-alist' 变量来自定义模糊音。
1.8.8 切换全角标点与半角标点
第一种方法:使用命令 `pyim-punctuation-toggle',全局切换。这个命令主要用来设置变量: `pyim-punctuation-translate-p', 用户也可以手动设置这个变量, 比如:
(setq pyim-punctuation-translate-p '(yes no auto)) ;使用全角标点。 (setq pyim-punctuation-translate-p '(no yes auto)) ;使用半角标点。 (setq pyim-punctuation-translate-p '(auto yes no)) ;中文使用全角标点,英文使用半角标点。
- 第二种方法:使用命令 `pyim-punctuation-translate-at-point' 只切换光标处标点的样式。
- 第三种方法:设置变量 `pyim-translate-trigger-char' ,输入变量设定的字符会切换光标处标点的样式。
1.8.9 手动加词和删词
- `pyim-create-Ncchar-word-at-point 这是一组命令,从光标前提取N个汉字字符组成字符串,并将其加入个人词库。
- `pyim-translate-trigger-char' 以默认设置为例:在“我爱吃红烧肉”后输入“5v” 可以将“爱吃红烧肉”这个词条保存到用户个人词库。
- `pyim-create-word-from-selection', 选择一个词条,运行这个命令后,就可以将这个词条添加到个人词库。
- `pyim-delete-word' 从个人词库中删除当前高亮选择的词条。
1.8.10 pyim 高级功能
- 根据环境自动切换到英文输入模式,使用 pyim-english-input-switch-functions 配置。
- 根据环境自动切换到半角标点输入模式,使用 pyim-punctuation-half-width-functions 配置。
注意:上述两个功能使用不同的变量设置,千万不要搞错。
1.8.10.1 根据环境自动切换到英文输入模式
| 探针函数 | 功能说明 |
|---|---|
| pyim-probe-program-mode | 如果当前的 mode 衍生自 prog-mode,那么仅仅在字符串和 comment 中开启中文输入模式 |
| pyim-probe-org-speed-commands | 解决 org-speed-commands 与 pyim 冲突问题 |
| pyim-probe-isearch-mode | 使用 isearch 搜索时,强制开启英文输入模式 |
| 注意:想要使用这个功能,pyim-isearch-mode 必须激活 | |
| pyim-probe-org-structure-template | 使用 org-structure-template 时,关闭中文输入模式 |
| 1. 当前字符为中文字符时,输入下一个字符时默认开启中文输入 | |
| pyim-probe-dynamic-english | 2. 当前字符为其他字符时,输入下一个字符时默认开启英文输入 |
| 3. 使用命令 pyim-convert-code-at-point 可以将光标前的拼音字符串强制转换为中文。 |
激活方式:
(setq-default pyim-english-input-switch-functions
'(probe-function1 probe-function2 probe-function3))
注:上述函数列表中,任意一个函数的返回值为 t 时,pyim 切换到英文输入模式。
1.8.10.2 根据环境自动切换到半角标点输入模式
| 探针函数 | 功能说明 |
|---|---|
| pyim-probe-punctuation-line-beginning | 行首强制输入半角标点 |
| pyim-probe-punctuation-after-punctuation | 半角标点后强制输入半角标点 |
激活方式:
(setq-default pyim-punctuation-half-width-functions
'(probe-function4 probe-function5 probe-function6))
注:上述函数列表中,任意一个函数的返回值为 t 时,pyim 切换到半角标点输入模式。
1.9 捐赠
您可以通过小额捐赠的方式支持 pyim 的开发工作,具体方式:
- 通过支付宝收款账户:tumashu@163.com
通过支付宝钱包扫描:

1.10 Tips
1.10.1 如何将个人词条导出到一个文件
使用命令:pyim-dcache-export-personal-dcache
1.10.2 pyim 出现错误时,如何开启 debug 模式
(setq debug-on-error t)
1.10.3 选词框弹出位置不合理或者选词框内容显示不全
可以通过设置 `pyim-tooltip-width-adjustment' 变量来手动校正。
- 选词框内容显示不全:增大变量值
- 选词框弹出位置不合理:减小变量值
1.10.4 如何查看 pyim 文档。
pyim 的文档隐藏在 comment 中,如果用户喜欢阅读 html 格式的文档,可以查看在线文档;
1.10.5 将光标处的拼音或者五笔字符串转换为中文 (与 vimim 的 “点石成金” 功能类似)
(global-set-key (kbd "M-i") 'pyim-convert-code-at-point)
1.10.6 如何添加自定义拼音词库
pyim 默认没有携带任何拼音词库,用户可以使用下面几种方式,获取质量较好的拼音词库:
1.10.6.1 第一种方式 (懒人推荐使用)
获取其他 pyim 用户的拼音词库,比如,某个同学测试 pyim 时创建了一个中文拼音词库,词条数量大约60万。
http://tumashu.github.io/pyim-bigdict/pyim-bigdict.pyim.gz
下载上述词库后,运行 `pyim-dicts-manager' ,按照命令提示,将下载得到的词库文件信息添加到 `pyim-dicts' 中,最后运行命令 `pyim-restart' 或者重启 emacs,这个词库使用 `utf-8-unix' 编码。
1.10.6.2 第二种方式 (Windows 用户推荐使用)
使用词库转换工具将其他输入法的词库转化为pyim使用的词库:这里只介绍windows平台下的一个词库转换软件:
- 软件名称: imewlconverter
- 中文名称: 深蓝词库转换
- 下载地址: https://github.com/studyzy/imewlconverter
- 依赖平台: Microsoft .NET Framework (>= 3.5)
使用方式:
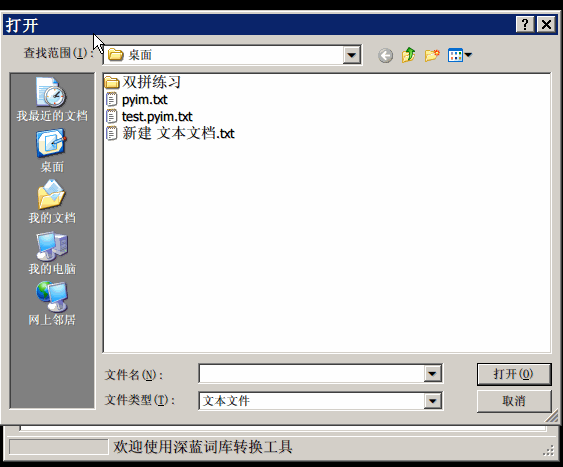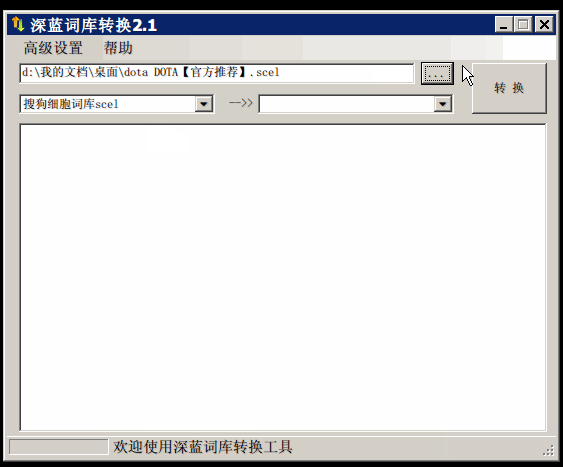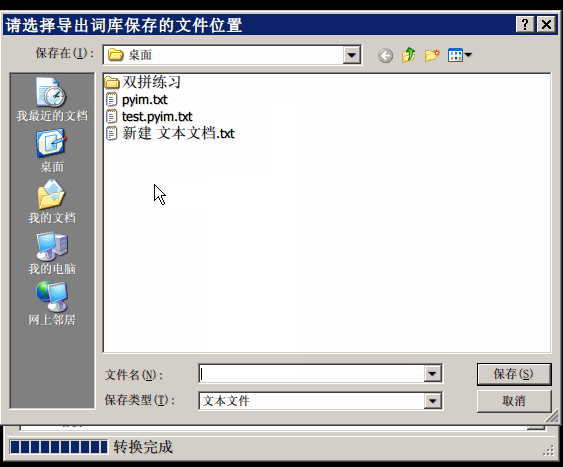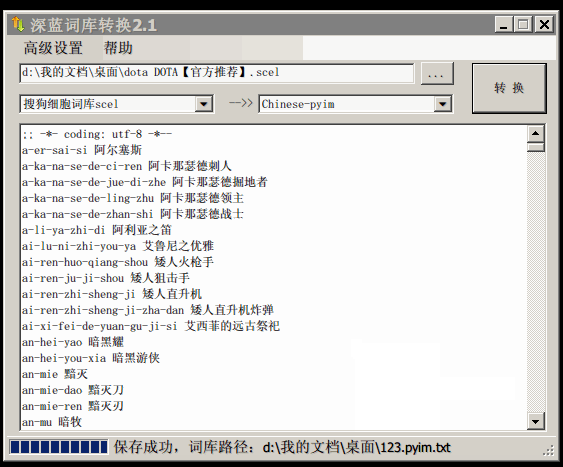
如果生成的词库词频不合理,可以按照下面的方式处理(非常有用的功能):
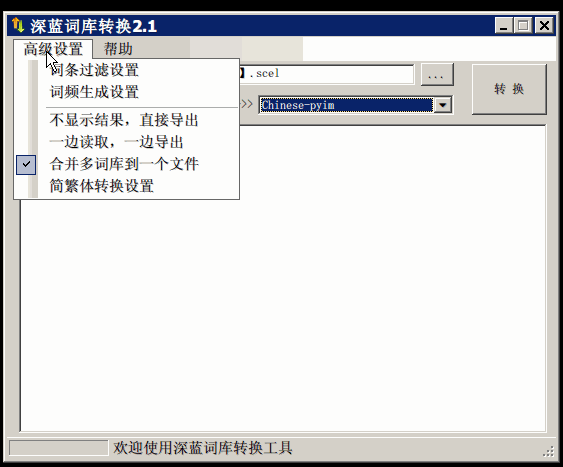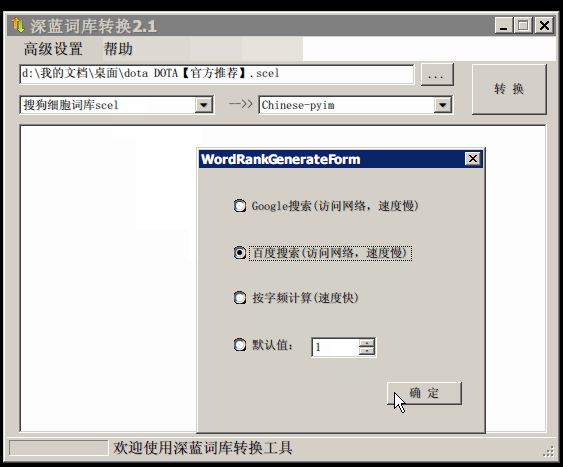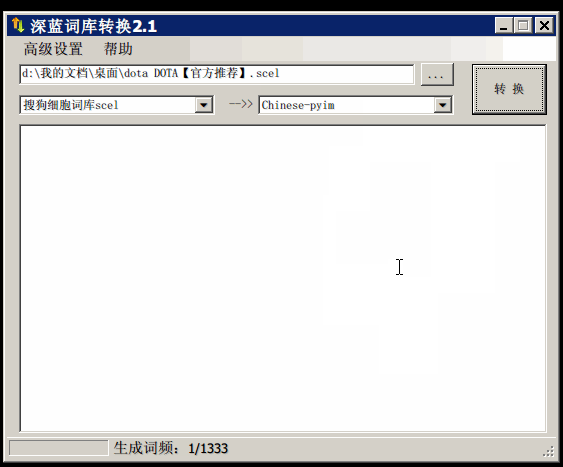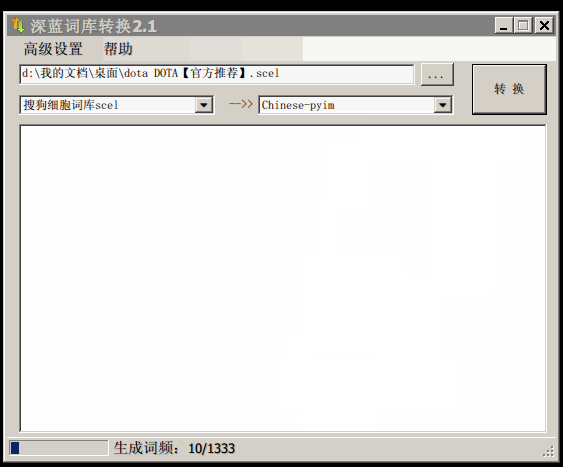
生成词库后,运行 `pyim-dicts-manager' ,按照命令提示,将转换得到的词库文件的信息添加到 `pyim-dicts' 中,完成后运行命令 `pyim-restart' 或者重启emacs。
1.10.6.3 第三种方式 (Linux & Unix 用户推荐使用)
E-Neo 同学编写了一个词库转换工具: scel2pyim , 可以将一个搜狗词库转换为 pyim 词库。
- 软件名称: scel2pyim
- 下载地址: https://github.com/E-Neo/scel2pyim
- 编写语言: C语言
1.10.7 如何手动安装和管理词库
这里假设有两个词库文件:
- /path/to/pyim-dict1.pyim
- /path/to/pyim-dict2.pyim
在~/.emacs文件中添加如下一行配置。
(setq pyim-dicts
'((:name "dict1" :file "/path/to/pyim-dict1.pyim")
(:name "dict2" :file "/path/to/pyim-dict2.pyim")))
注意事项:
- 只有 :file 是必须设置的。
- 必须使用词库文件的绝对路径。
- 词库文件的编码必须为 utf-8-unix,否则会出现乱码。
1.10.8 Emacs 启动时加载 pyim 词库
(add-hook 'emacs-startup-hook
#'(lambda () (pyim-restart-1 t)))
1.10.9 将汉字字符串转换为拼音字符串
下面两个函数可以将中文字符串转换的拼音字符串或者列表,用于 emacs-lisp 编程。
- `pyim-hanzi2pinyin' (考虑多音字)
- `pyim-hanzi2pinyin-simple' (不考虑多音字)
1.10.10 中文分词
pyim 包含了一个简单的分词函数:`pyim-cstring-split-to-list', 可以将一个中文字符串分成一个词条列表,比如:
(("天安" 5 7)
我爱北京天安门 -> ("天安门" 5 8)
("北京" 3 5)
("我爱" 1 3))
其中,每一个词条列表中包含三个元素,第一个元素为词条本身,第二个元素为词条相对于字符串的起始位置,第三个元素为词条结束位置。
另一个分词函数是 `pyim-cstring-split-to-string', 这个函数将生成一个新的字符串,在这个字符串中,词语之间用空格或者用户自定义的分隔符隔开。
注意,上述两个分词函数使用暴力匹配模式来分词,所以,不能检测出 pyim 词库中不存在的中文词条。
1.10.11 获取光标处的中文词条
pyim 包含了一个简单的命令:`pyim-cwords-at-point', 这个命令可以得到光标处的英文或者中文词条的 *列表*,这个命令依赖分词函数: `pyim-cstring-split-to-list'。
1.10.12 让 `forward-word' 和 `back-backward’ 在中文环境下正常工作
中文词语没有强制用空格分词,所以 Emacs 内置的命令 `forward-word' 和 `backward-word' 在中文环境不能按用户预期的样子执行,而是 forward/backward “句子” ,pyim 自带的两个命令可以在中文环境下正常工作:
- `pyim-forward-word
- `pyim-backward-word
用户只需将其绑定到快捷键上就可以了,比如:
(global-set-key (kbd "M-f") 'pyim-forward-word) (global-set-key (kbd "M-b") 'pyim-backward-word)
1.10.13 为 isearch 相关命令添加拼音搜索支持
pyim 安装后,可以通过下面的设置开启拼音搜索功能:
(pyim-isearch-mode 1)
注意:这个功能有一些限制,搜索字符串中只能出现 “a-z” 和 “’”,如果有其他字符(比如 regexp 操作符),则自动关闭拼音搜索功能。
开启这个功能后,一些 isearch 扩展有可能失效,如果遇到这种问题,只能禁用这个 Minor-mode,然后联系 pyim 的维护者,看有没有法子实现兼容。
用户激活这个 mode 后,可以使用下面的方式强制关闭 isearch 搜索框中文输入(即使在 pyim 激活的时候)。
(setq-default pyim-english-input-switch-functions
'(pyim-probe-isearch-mode))
2 核心代码
2.1 require + defcustom + defvar
(require 'cl-lib) (require 'help-mode) (require 'pos-tip) (require 'popup) (require 'async) (require 'pyim-pymap)
(defgroup pyim nil "Chinese pinyin input method" :group 'leim)
(defcustom pyim-directory (locate-user-emacs-file "pyim/") "一个目录,用于保存与 pyim 相关的文件." :group 'pyim)
(defcustom pyim-dcache-directory (locate-user-emacs-file "pyim/dcache") "一个目录,用于保存 pyim 词库对应的 cache 文件." :group 'pyim)
(defcustom pyim-dicts nil "一个列表,用于保存 `pyim' 的词库信息. 每一个 element 都代表一条词库的信息, 用户可以使用词库管理命令 `pyim-dicts-manager' 来添加词库信息,每一条词库信息都使用一个 plist 来表示,比如: (:name \"100万大词库\" :file \"/path/to/pinyin-bigdict.pyim\") 其中: 1. `:name' 代表词库名称,用户可以按照喜好来确定(可选项)。 2. `:file' 表示词库文件, 另外一个与这个变量功能类似的变量是: `pyim-extra-dicts', 专门 用于和 elpa 格式的词库包集成。" :group 'pyim :type 'list)
(defcustom pyim-punctuation-dict '(("'" "‘" "’") ("\"" "“" "”") ("_" "―") ("^" "…") ("]" "】") ("[" "【") ("@" "◎") ("?" "?") (">" "》") ("=" "=") ("<" "《") (";" ";") (":" ":") ("/" "、") ("." "。") ("-" "-") ("," ",") ("+" "+") ("*" "×") (")" ")") ("(" "(") ("&" "※") ("%" "%") ("$" "¥") ("#" "#") ("!" "!") ("`" "・") ("~" "~") ("}" "』") ("|" "÷") ("{" "『")) "标点符号表." :group 'pyim :type 'list)
(defcustom pyim-default-scheme 'quanpin "设置 pyim 使用哪一种拼音方案,默认使用全拼输入." :group 'pyim)
(defcustom pyim-schemes '((quanpin :document "全拼输入法方案(不可删除)。" :class quanpin :first-chars "abcdefghjklmnopqrstwxyz" :rest-chars "vmpfwckzyjqdltxuognbhsrei'-a" :prefer-trigger-chars "v") (wubi :document "五笔输入法。" :class xingma :first-chars "abcdefghijklmnopqrstuvwxyz" :rest-chars "abcdefghijklmnopqrstuvwxyz" :code-prefix "." ;五笔词库中所有的 code 都以 "." 开头,防止和拼音词库冲突。 :code-split-length 4 ;默认将用户输入切成 4 个字符长的 code 列表(不计算 code-prefix) :code-maximum-length 4 ;五笔词库中,code 的最大长度(不计算 code-prefix) :prefer-trigger-chars nil) (cangjie :document "倉頡输入法。" :class xingma :first-chars "abcdefghijklmnopqrstuvwxyz" :rest-chars "abcdefghijklmnopqrstuvwxyz" :code-prefix "@" ;仓颉输入法词库中所有的 code 都以 "@" 开头,防止词库冲突。 :code-split-length 5 ;默认将用户输入切成 5 个字符长的 code 列表(不计算 code-prefix) :code-maximum-length 5 ;仓颉词库中,code 的最大长度(不计算 code-prefix) :prefer-trigger-chars nil) (pyim-shuangpin :document "与 pyim 配合良好的双拼输入法方案,源自小鹤双拼方案。" :class shuangpin :first-chars "abcdefghijklmnpqrstuvwxyz" :rest-chars "abcdefghijklmnopqrstuvwxyz" :prefer-trigger-chars "o" :keymaps (("a" "a" "a") ("b" "b" "in") ("c" "c" "ao") ("d" "d" "ai") ("e" "e" "e") ("f" "f" "en") ("g" "g" "eng") ("h" "h" "ang") ("i" "ch" "i") ("j" "j" "an") ("k" "k" "ing" "uai") ("l" "l" "iang" "uang") ("m" "m" "ian") ("n" "n" "iao") ("o" "o" "uo" "o") ("p" "p" "ie") ("q" "q" "iu") ("r" "r" "uan") ("s" "s" "iong" "ong") ("t" "t" "ue" "ve") ("u" "sh" "u") ("v" "zh" "v" "ui") ("w" "w" "ei") ("x" "x" "ia" "ua") ("y" "y" "un") ("z" "z" "ou") ("aa" "a") ("aj" "an") ("ad" "ai") ("ac" "ao") ("ah" "ang") ("ee" "e") ("ew" "ei") ("ef" "en") ("er" "er") ("eg" "eng") ("ag" "ng") ("ao" "o") ("au" "ou"))) (microsoft-shuangpin :document "微软双拼方案。" :class shuangpin :first-chars "abcdefghijklmnopqrstuvwxyz" :rest-chars "abcdefghijklmnopqrstuvwxyz;" :prefer-trigger-chars nil :keymaps (("a" "a" "a") ("b" "b" "ou") ("c" "c" "iao") ("d" "d" "uang" "iang") ("e" "e" "e") ("f" "f" "en") ("g" "g" "eng") ("h" "h" "ang") ("i" "ch" "i") ("j" "j" "an") ("k" "k" "ao") ("l" "l" "ai") ("m" "m" "ian") ("n" "n" "in") ("o" "o" "uo" "o") ("p" "p" "un") ("q" "q" "iu") ("r" "r" "uan" "er") ("s" "s" "iong" "ong") ("t" "t" "ue") ("u" "sh" "u") ("v" "zh" "ve" "ui") ("w" "w" "ia" "ua") ("x" "x" "ie") ("y" "y" "uai" "v") ("z" "z" "ei") (";" ";" "ing") ("oa" "a") ("oj" "an") ("ol" "ai") ("ok" "ao") ("oh" "ang") ("oe" "e") ("oz" "ei") ("of" "en") ("or" "er") ("og" "eng") ("oo" "o") ("ob" "ou"))) (xiaohe-shuangpin :document "小鹤双拼输入法方案。" :class shuangpin :first-chars "abcdefghijklmnopqrstuvwxyz" :rest-chars "abcdefghijklmnopqrstuvwxyz" :prefer-trigger-chars nil :keymaps (("a" "a" "a") ("b" "b" "in") ("c" "c" "ao") ("d" "d" "ai") ("e" "e" "e") ("f" "f" "en") ("g" "g" "eng") ("h" "h" "ang") ("i" "ch" "i") ("j" "j" "an") ("k" "k" "ing" "uai") ("l" "l" "iang" "uang") ("m" "m" "ian") ("n" "n" "iao") ("o" "o" "uo" "o") ("p" "p" "ie") ("q" "q" "iu") ("r" "r" "uan") ("s" "s" "iong" "ong") ("t" "t" "ue" "ve") ("u" "sh" "u") ("v" "zh" "v" "ui") ("w" "w" "ei") ("x" "x" "ia" "ua") ("y" "y" "un") ("z" "z" "ou") ("aa" "a") ("aj" "an") ("ad" "ai") ("ac" "ao") ("ah" "ang") ("ee" "e") ("ew" "ei") ("ef" "en") ("er" "er") ("eg" "eng") ("og" "ng") ("oo" "o") ("ou" "ou")))) "Pyim 支持的所有拼音方案.")
(defcustom pyim-translate-trigger-char "v" "用于触发特殊操作的字符,相当与单字快捷键. pyim 内建的功能有: 1. 光标前面的字符为标点符号时,按这个字符可以切换前面的标 点符号的样式(半角/全角) 2. 当光标前面为中文字符串时,输入 <num>v 可以用于保存自定义词条。 3. 其它。 注意:单字快捷键受到拼音方案的限制,比如:全拼输入法可以将其设置为v, 但双拼输入法下设置 v 可能就不行,所以,pyim 首先会检查 当前拼音方案下,这个快捷键设置是否合理有效,如果不是一个合理的设置, 则使用拼音方案默认的 :prefer-trigger-chars 。 具体请参考 `pyim-translate-get-trigger-char' 。" :group 'pyim :type 'character)
(defcustom pyim-fuzzy-pinyin-alist '(("en" "eng") ("in" "ing") ("un" "ong")) "设定糢糊音." :group 'pyim)
(defface pyim-dagger-face '((t (:underline t))) "dagger 字符串的 face" :group 'pyim)
(defcustom pyim-english-input-switch-functions nil "让 pyim 开启英文输入功能. 这个变量的取值为一个函数列表,这个函数列表中的任意一个函数的 运行结果为 t 时,pyim 开启英文输入功能。" :group 'pyim)
(defcustom pyim-punctuation-half-width-functions nil "让 pyim 输入半角标点. 取值为一个函数列表,这个函数列表中的任意一个函数的运行结果为 t 时, pyim 输入半角标点,函数列表中每个函数都有一个参数:char ,表示 最后输入的一个字符,具体见: `pyim-translate' 。" :group 'pyim)
(defcustom pyim-wash-function 'pyim-wash-current-line-function "清洗光标前面的文字内容. 这个函数与『单字快捷键配合使用』,当光标前面的字符为汉字字符时, 按 `pyim-translate-trigger-char' 对应字符,可以调用这个函数来清洗 光标前面的文字内容。" :group 'pyim :type 'function)
(defcustom pyim-page-length 5 "每页显示的词条数目." :group 'pyim :type 'number)
(defcustom pyim-page-tooltip 'popup "如何绘制 pyim 选词框. 1. 当这个变量取值为 t 或者 'popup 时,使用 popup-el 包来绘制选词框; 2. 当取值为 pos-tip 时,使用 pos-tip 包来绘制选词框; 3. 当取值为 minibuffer 或者 nil 时,使用 minibuffer 做为选词框;" :group 'pyim)
(defcustom pyim-page-style 'two-lines "这个变量用来控制选词框的格式. pyim 内建的有三种选词框格式: 1. one-line 单行选词框 2. two-lines 双行选词框 3. vertical 垂直选词框" :group 'pyim :type 'symbol)
(defcustom pyim-page-select-finish-hook nil "Pyim 选词完成时运行的 hook." :group 'pyim :type 'hook)
(defface pyim-page-selected-word-face '((t (:background "gray40"))) "选词框中已选词条的 face 注意:当使用 minibuffer 为选词框时,这个选项才有用处。" :group 'pyim)
(defcustom pyim-page-tooltip-width-adjustment 1.2 "校正 tooltip 选词框宽度的数值,表示校正后的宽度是未校正前宽度的倍数. 由于字体设置等原因,pos-tip 选词框实际宽度会比 *预期宽度* 偏大或者偏小, 这时,有可能会出现选词框词条显示不全或者选词框弹出位置不合理等问题。用户可以通过 增大或者减小这个变量来改变 tooltip 选词框的宽度,取值大概在 0.5 ~ 2.0 范围之内。 注:这个选项只适用于 `pyim-page-tooltip' 取值为 'pos-tip 的时候。" :group 'pyim)
(defvar pyim-debug nil) (defvar pyim-title "灵通" "Pyim 在 mode-line 中显示的名称.") (defvar pyim-extra-dicts nil "与 `pyim-dicts' 类似, 用于和 elpa 格式的词库包集成。.")
(defvar pyim-backends '(personal-dcache-words common-dcache-words pinyin-chars jianpin-words znabc-words xingma-words) "Pyim 词语获取 backends. 当前支持: 1. `personal-dcache-words' 从 `pyim-dcache-icode2word' 中获取词条。 2. `common-dcache-words' 从 `pyim-dcache-code2word' 中获取词条。 3. `pinyin-chars' 逐一获取一个拼音对应的多个汉字。 4. `jianpin-words' 获取简拼对应的词条,如果输入 \"ni-hao\", 那么同时搜索 code 为 \"n-h\" 的词条。 5. `znabc-words' 类似智能ABC的词语获取方式(源于 emacs-eim). 6. `xingma-words' 专门用于处理五笔等基于形码的输入法的 backend.")
(defvar pyim-pinyin-shen-mu '("b" "p" "m" "f" "d" "t" "n" "l" "g" "k" "h" "j" "q" "x" "z" "c" "s" "zh" "ch" "sh" "r" "y" "w"))
(defvar pyim-pinyin-yun-mu '("a" "o" "e" "i" "u" "v" "ai" "ei" "ui" "ao" "ou" "iu" "ie" "ia" "ua" "ve" "er" "an" "en" "in" "un" "vn" "ang" "iong" "eng" "ing" "ong" "uan" "uang" "ian" "iang" "iao" "ue" "uai" "uo"))
(defvar pyim-pinyin-valid-yun-mu '("a" "o" "e" "ai" "ei" "ui" "ao" "ou" "er" "an" "en" "ang" "eng"))
(defvar pyim-entered-code "" "用户已经输入的 code,由用户输入的字符连接而成.")
(defvar pyim-dagger-str "" "光标处带下划线字符串. 输入法运行的时候,会在光标处会插入一个带下划线字符串,这个字符串 提示用户当前选择的词条或者当前输入的 code 等许多有用的信息。 pyim 称这个字符串为 \"dragger string\", 向 \"匕首\" 一样插入 当前 buffer 的光标处。")
(defvar pyim-input-ascii nil "是否开启 pyim 英文输入模式.") (defvar pyim-force-input-chinese nil "是否强制开启中文输入模式.")
(defvar pyim-current-choices nil "所有可选的词条,是一个list. 1. CAR 部份是可选的词条,一般是一个字符串列表。 也可以含有list。但是包含的list第一个元素必须是将要插入的字符串。 2. CDR 部分是一个 Association list。通常含有这样的内容: 1. pos 上次选择的位置 2. completion 下一个可能的字母(如果 pyim-do-completion 为 t)")
(defvar pyim-translating nil "记录是否在转换状态.")
(defvar pyim-dagger-overlay nil "用于保存 dagger 的 overlay.")
(defvar pyim-code-position nil) (defvar pyim-scode-list nil "Scode 组成的 list. pyim 会将一个 code 分解为一个或者多个 scode (splited code), 这个变量用于保存分解得到的结果。")
(defvar pyim-current-pos nil "当前选择的词条在 ‘pyim-current-choices’ 中的位置.")
(defvar pyim-load-hook nil) (defvar pyim-active-hook nil)
(defvar pyim-punctuation-translate-p '(auto yes no) "The car of its value will control the translation of punctuation.")
(defvar pyim-punctuation-pair-status '(("\"" nil) ("'" nil)) "成对标点符号切换状态.")
(defvar pyim-punctuation-escape-list (number-sequence ?0 ?9) "Punctuation will not insert after this characters. If you don't like this funciton, set the variable to nil")
(defvar pyim-pinyin2cchar-cache1 nil "拼音查汉字功能需要的变量.") (defvar pyim-pinyin2cchar-cache2 nil "拼音查汉字功能需要的变量.") (defvar pyim-pinyin2cchar-cache3 nil "拼音查汉字功能需要的变量.") (defvar pyim-cchar2pinyin-cache nil "汉字转拼音功能需要的变量.")
Pyim 词库缓存文件,注意:变量名称中不能出现 ":" 等,不能作为文件名称的字符。
(defvar pyim-dcache-code2word nil) (defvar pyim-dcache-code2word-md5 nil) (defvar pyim-dcache-word2code nil) (defvar pyim-dcache-word2count nil) (defvar pyim-dcache-shortcode2word nil) (defvar pyim-dcache-icode2word nil) (defvar pyim-dcache-iword2count nil) (defvar pyim-dcache-ishortcode2word nil)
(defvar pyim-dcache-update-shortcode2word-dcache nil)
(defvar pyim-dcache-update-icode2word-dcache nil) (defvar pyim-dcache-update-ishortcode2word-dcache nil)
(defvar pyim-mode-map (let ((map (make-sparse-keymap)) (i ?\ )) (while (< i 127) (define-key map (char-to-string i) 'pyim-self-insert-command) (setq i (1+ i))) (setq i 128) (while (< i 256) (define-key map (vector i) 'pyim-self-insert-command) (setq i (1+ i))) (dolist (i (number-sequence ?1 ?9)) (define-key map (char-to-string i) 'pyim-page-select-word-by-number)) (define-key map " " 'pyim-page-select-word) (define-key map [backspace] 'pyim-delete-last-char) (define-key map [delete] 'pyim-delete-last-char) (define-key map [M-backspace] 'pyim-backward-kill-py) (define-key map [M-delete] 'pyim-backward-kill-py) (define-key map [C-backspace] 'pyim-backward-kill-py) (define-key map [C-delete] 'pyim-backward-kill-py) (define-key map "\177" 'pyim-delete-last-char) (define-key map "\C-n" 'pyim-page-next-page) (define-key map "\C-p" 'pyim-page-previous-page) (define-key map "\C-f" 'pyim-page-next-word) (define-key map "\C-b" 'pyim-page-previous-word) (define-key map "=" 'pyim-page-next-page) (define-key map "-" 'pyim-page-previous-page) (define-key map "\M-n" 'pyim-page-next-page) (define-key map "\M-p" 'pyim-page-previous-page) (define-key map "\C-m" 'pyim-quit-no-clear) (define-key map [return] 'pyim-quit-no-clear) (define-key map "\C-c" 'pyim-quit-clear) map) "Pyim 的 Keymap.")
2.2 将变量转换为 local 变量
(defvar pyim-local-variable-list '(pyim-entered-code pyim-dagger-str pyim-current-choices pyim-current-pos pyim-input-ascii pyim-english-input-switch-functions pyim-punctuation-half-width-functions pyim-translating pyim-dagger-overlay pyim-load-hook pyim-active-hook input-method-function inactivate-current-input-method-function describe-current-input-method-function pyim-punctuation-translate-p pyim-punctuation-pair-status pyim-punctuation-escape-list pyim-scode-list pyim-code-position) "A list of buffer local variable.")
(dolist (var pyim-local-variable-list)
(make-variable-buffer-local var)
(put var 'permanent-local t))
2.3 "汉字 -> 拼音" 以及 "拼音 -> 汉字" 的转换函数
(defun pyim-pinyin2cchar-cache-create (&optional force) "构建 pinyin 到 chinese char 的缓存. 用于加快搜索速度,这个函数将缓存保存到 `pyim-pinyin2cchar-cache' 变量中, 如果 FORCE 设置为 t, 强制更新索引。" (when (or force (or (not pyim-pinyin2cchar-cache1) (not pyim-pinyin2cchar-cache2))) (setq pyim-pinyin2cchar-cache1 (make-hash-table :size 50000 :test #'equal)) (setq pyim-pinyin2cchar-cache2 (make-hash-table :size 50000 :test #'equal)) (setq pyim-pinyin2cchar-cache3 (make-hash-table :size 50000 :test #'equal)) (dolist (x pyim-pymap) (let* ((py (car x)) (cchars (cdr x)) (n (min (length py) 7))) (puthash py cchars pyim-pinyin2cchar-cache1) (puthash py (cdr (split-string (car cchars) "")) pyim-pinyin2cchar-cache2) (dotimes (i n) (let* ((key (substring py 0 (+ i 1))) (orig-value (gethash key pyim-pinyin2cchar-cache3))) (puthash key (delete-dups `(,@orig-value ,@cchars)) pyim-pinyin2cchar-cache3)))))))
(defun pyim-pinyin2cchar-get (pinyin &optional equal-match return-list) "获取拼音与 PINYIN 想匹配的所有汉字. 比如: “man” -> (\"忙茫盲芒氓莽蟒邙漭硭\" \"满慢漫曼蛮馒瞒蔓颟谩墁幔螨鞔鳗缦熳镘\") 如果 EQUAL-MATCH 是 non-nil, 获取和 PINYIN 完全匹配的汉字。 如果 RETURN-LIST 是 non-nil, 返回一个由单个汉字字符串组成的列表。 (\"满\" \"慢\" \"漫\" ...)" (pyim-pinyin2cchar-cache-create) (when (and pinyin (stringp pinyin)) (if equal-match (if return-list (gethash pinyin pyim-pinyin2cchar-cache2) (gethash pinyin pyim-pinyin2cchar-cache1)) (gethash pinyin pyim-pinyin2cchar-cache3))))
2.3.1 查询某个汉字的拼音
pyim 在特定的时候需要读取一个汉字的拼音,这个工作由下面函数完成:
函数 `pyim-cchar2pinyin-get' 从 `pyim-cchar2pinyin-cache' 查询得到一个汉字字符的拼音, 例如:
(pyim-cchar2pinyin-get ?我)
结果为:
("wo")
我们用全局变量 `pyim-cchar2pinyin-cache' 来保存这个 hash table 。
这个例子中的语句用于调试上述三个函数。
(setq pyim-cchar2pinyin-cache nil) (pyim-cchar2pinyin-create-cache) (pyim-cchar2pinyin-get ?你) (pyim-cchar2pinyin-get "你")
(defun pyim-cchar2pinyin-get (char-or-str) "Get the code of CHAR-OR-STR." (pyim-cchar2pinyin-cache-create) (let ((key (if (characterp char-or-str) (char-to-string char-or-str) char-or-str))) (when (= (length key) 1) (gethash key pyim-cchar2pinyin-cache))))
(defun pyim-cchar2pinyin-cache-create (&optional force) "Build pinyin cchar->pinyin hashtable from `pyim-pymap'. If FORCE is non-nil, FORCE build." (when (or force (not pyim-cchar2pinyin-cache)) (setq pyim-cchar2pinyin-cache (make-hash-table :size 50000 :test #'equal)) (dolist (x pyim-pymap) (let ((py (car x)) (cchar-list (string-to-list (car (cdr x))))) (dolist (cchar cchar-list) (let* ((key (char-to-string cchar)) (cache (gethash key pyim-cchar2pinyin-cache))) (if cache (puthash key (append (list py) cache) pyim-cchar2pinyin-cache) (puthash key (list py) pyim-cchar2pinyin-cache))))))))
2.4 输入法启动和重启
pyim 使用 emacs 官方自带的输入法框架来启动输入法和重启输入法。所以我们首先需要使用 emacs 自带的命令 `register-input-method' 注册一个输入法。
注册输入法
(register-input-method "pyim" "euc-cn" 'pyim-start pyim-title)
真正启动 pyim 的命令是 `pyim-start' ,这个命令做如下工作:
- 重置 `pyim-local-variable-list' 中所有的 local 变量。
- 使用 `pyim-cchar2pinyin-create-cache' 创建汉字到拼音的 hash table 。
- 运行hook: `pyim-load-hook'。
- 将 `pyim-dcache-save-caches' 命令添加到 `kill-emacs-hook' , emacs 关闭之前将 `pyim-dcache-icode2word' 和 `pyim-dcache-iword2count' 保存到文件,供以后使用。
- 设定变量:
- `input-method-function'
- `deactivate-current-input-method-function'
- 运行 `pyim-active-hook'
`pyim-start' 先后会运行两个 hook,所以我们需要事先定义:
`pyim-restart' 用于重启 pyim,其过程和 `pyim-start' 类似,只是在输入法重启之前,询问用户,是否保存个人词频信息。
(defun pyim-start (name &optional active-func restart save-personal-dcache refresh-common-dcache) "Start pyim. TODO: Document NAME ACTIVE-FUNC RESTART SAVE-PERSONAL-DCACHE REFRESH-COMMON-DCACHE" (interactive) (mapc 'kill-local-variable pyim-local-variable-list) (mapc 'make-local-variable pyim-local-variable-list) (when (and restart save-personal-dcache) (pyim-dcache-save-caches)) ;; 设置于 dcache 相关的几个变量。 (pyim-dcache-init-variables) ;; 使用 pyim-dcache-iword2count 中的信息对 personal 缓存中的词频进行调整。 (pyim-dcache-update-icode2word-dcache restart) ;; 创建简拼缓存, 比如 "ni-hao" -> "n-h" (pyim-dcache-update-ishortcode2word-dcache restart) (pyim-cchar2pinyin-cache-create) (pyim-pinyin2cchar-cache-create) (run-hooks 'pyim-load-hook) ;; 如果 `pyim-dicts' 有变化,重新生成 `pyim-dcache-code2word' 缓存。 (pyim-dcache-update-code2word-dcache refresh-common-dcache) ;; 这个命令 *当前* 主要用于五笔输入法。 (pyim-dcache-update-shortcode2word-dcache restart) (unless (member 'pyim-dcache-save-caches kill-emacs-hook) (add-to-list 'kill-emacs-hook 'pyim-dcache-save-caches)) (setq input-method-function 'pyim-input-method) (setq deactivate-current-input-method-function 'pyim-inactivate) ;; (setq describe-current-input-method-function 'pyim-help) ;; If we are in minibuffer, turn off the current input method ;; before exiting. (when (eq (selected-window) (minibuffer-window)) (add-hook 'minibuffer-exit-hook 'pyim-exit-from-minibuffer)) (run-hooks 'pyim-active-hook) (when restart (message "pyim 重启完成。")) nil)
(defun pyim-exit-from-minibuffer () "Pyim 从 minibuffer 退出." (deactivate-input-method) (when (<= (minibuffer-depth) 1) (remove-hook 'minibuffer-exit-hook 'quail-exit-from-minibuffer)))
(defun pyim-restart () "重启 pyim,不建议用于编程环境." (interactive (let ((save-personal-dcache (yes-or-no-p "重启 pyim 前,需要保存个人词频信息吗? ")) (refresh-common-dcache (yes-or-no-p "需要强制刷新词库缓存吗? "))) (pyim-restart-1 save-personal-dcache refresh-common-dcache))))
(defun pyim-restart-1 (&optional save-personal-dcache refresh-common-dcache) "重启 pyim,用于编程环境. 当 SAVE-PERSONAL-DCACHE 是 non-nil 时,保存个人词库文件。 当 REFRESH-COMMON-DCACHE 是 non-nil 时,强制刷新词库缓存。" (pyim-start "pyim" nil t save-personal-dcache refresh-common-dcache))
2.5 处理词库文件
2.5.1 自定义词库
2.5.1.1 词库文件格式
pyim 使用的词库文件是简单的文本文件,编码强制为 'utf-8-unix, 结构类似:
ni-bu-hao 你不好 ni-hao 你好 妮好 你豪
第一个空白字符之前的内容为 code,空白字符之后为中文词条列表。词库不处理中文标点符号。
我们使用变量 `pyim-dicts' 和 `pyim-extra-dicts' 来设定词库文件的信息:
- `:name' 用户给词库设定的名称(可选项)。
- `:file' 词库文件的绝对路径。
(defun pyim-dcache-update-code2word-dcache (&optional force) "读取并加载词库. 读取 `pyim-dicts' 和 `pyim-extra-dicts' 里面的词库文件,生成对应的 词库缓冲文件,然后加载词库缓存。 如果 FORCE 为真,强制加载。" (interactive) (let* ((version "v1") ;当需要强制更新 dict 缓存时,更改这个字符串。 (dict-files (mapcar #'(lambda (x) (unless (plist-get x :disable) (plist-get x :file))) `(,@pyim-dicts ,@pyim-extra-dicts))) (dicts-md5 (md5 (prin1-to-string (mapcar #'(lambda (file) (list version file (nth 5 (file-attributes file 'string)))) dict-files)))) (code2word-file (pyim-dcache-get-path 'pyim-dcache-code2word)) (word2code-file (pyim-dcache-get-path 'pyim-dcache-word2code)) (code2word-md5-file (pyim-dcache-get-path 'pyim-dcache-code2word-md5))) (when (or force (not (equal dicts-md5 (pyim-dcache-get-value-from-file code2word-md5-file)))) (async-start `(lambda () ,(async-inject-variables "^load-path$") ,(async-inject-variables "^exec-path$") ,(async-inject-variables "^pyim-.+?directory$") (require 'pyim) (let ((dcache (pyim-dcache-generate-dcache-file ',dict-files ,code2word-file))) (pyim-dcache-generate-word2code-dcache-file dcache ,word2code-file)) (pyim-dcache-save-value-to-file ',dicts-md5 ,code2word-md5-file)) `(lambda (result) (pyim-dcache-set-variable 'pyim-dcache-code2word t) (pyim-dcache-set-variable 'pyim-dcache-word2code t))))))
(defun pyim-dcache-update-ishortcode2word-dcache (&optional force) "读取 ‘pyim-dcache-icode2word’ 中的词库,创建 *简拼* 缓存,然后加载这个缓存. 如果 FORCE 为真,强制加载缓存。" (interactive) (when (or force (not pyim-dcache-update-ishortcode2word-dcache)) (async-start `(lambda () ,(async-inject-variables "^load-path$") ,(async-inject-variables "^exec-path$") ,(async-inject-variables "^pyim-.+?directory$") (require 'pyim) (pyim-dcache-set-variable 'pyim-dcache-icode2word) (pyim-dcache-set-variable 'pyim-dcache-iword2count) (setq pyim-dcache-ishortcode2word (make-hash-table :test #'equal)) (maphash #'(lambda (key value) (let ((newkey (mapconcat #'(lambda (x) (substring x 0 1)) (split-string key "-") "-"))) (puthash newkey (delete-dups `(,@value ,@(gethash newkey pyim-dcache-ishortcode2word))) pyim-dcache-ishortcode2word))) pyim-dcache-icode2word) (maphash #'(lambda (key value) (puthash key (pyim-dcache-sort-words value) pyim-dcache-ishortcode2word)) pyim-dcache-ishortcode2word) (pyim-dcache-save-variable 'pyim-dcache-ishortcode2word)) `(lambda (result) (setq pyim-dcache-create-abbrev-dcache-p t) (pyim-dcache-set-variable 'pyim-dcache-ishortcode2word t)))))
(defun pyim-dcache-update-icode2word-dcache (&optional force) "对 personal 缓存中的词条进行排序,加载排序后的结果. 在这个过程中使用了 pyim-dcache-icode2count 中记录的词频信息。 如果 FORCE 为真,强制排序。" (interactive) (when (or force (not pyim-dcache-update-icode2word-dcache)) (async-start `(lambda () ,(async-inject-variables "^load-path$") ,(async-inject-variables "^exec-path$") ,(async-inject-variables "^pyim-.+?directory$") (require 'pyim) (pyim-dcache-set-variable 'pyim-dcache-icode2word) (pyim-dcache-set-variable 'pyim-dcache-iword2count) (maphash #'(lambda (key value) (puthash key (pyim-dcache-sort-words value) pyim-dcache-icode2word)) pyim-dcache-icode2word) (pyim-dcache-save-variable 'pyim-dcache-icode2word) nil) `(lambda (result) (setq pyim-dcache-update-icode2word-dcache t) (pyim-dcache-set-variable 'pyim-dcache-icode2word t)))))
(defun pyim-dcache-update-shortcode2word-dcache (&optional force) "使用 ‘pyim-dcache-code2word’ 中的词条,创建 简写code 词库缓存并加载. 如果 FORCE 为真,强制运行。" (interactive) (when (or force (not pyim-dcache-update-shortcode2word-dcache)) (async-start `(lambda () ,(async-inject-variables "^load-path$") ,(async-inject-variables "^exec-path$") ,(async-inject-variables "^pyim-.+?directory$") (require 'pyim) (pyim-dcache-set-variable 'pyim-dcache-code2word) (pyim-dcache-set-variable 'pyim-dcache-iword2count) (setq pyim-dcache-shortcode2word (make-hash-table :test #'equal)) (maphash #'(lambda (key value) (dolist (x (pyim-dcache-return-shortcode key)) (puthash x (mapcar #'(lambda (word) ;; 这个地方的代码用于实现五笔 code 自动提示功能, ;; 比如输入 'aa' 后得到选词框: ;; ---------------------- ;; | 1. 莁aa 2.匶wv ... | ;; ---------------------- (if (string-match-p ":" word) word (concat word ":" (substring key (length x))))) (delete-dups `(,@value ,@(gethash x pyim-dcache-shortcode2word)))) pyim-dcache-shortcode2word))) pyim-dcache-code2word) (maphash #'(lambda (key value) (puthash key (pyim-dcache-sort-words value) pyim-dcache-shortcode2word)) pyim-dcache-shortcode2word) (pyim-dcache-save-variable 'pyim-dcache-shortcode2word) nil) `(lambda (result) (setq pyim-dcache-update-shortcode2word-dcache t) (pyim-dcache-set-variable 'pyim-dcache-shortcode2word t)))))
(defun pyim-dcache-return-shortcode (code) "获取一个 CODE 的所有简写. 比如:.nihao -> .nihao .niha .nih .ni .n" (when (and (> (length code) 0) (not (string-match-p "-" code)) (pyim-string-match-p "^[[:punct:]]" code)) (let* ((code1 (substring code 1)) (prefix (substring code 0 1)) (n (length code1)) results) (dotimes (i n) (when (> i 1) (push (concat prefix (substring code1 0 i)) results))) results)))
(defun pyim-dcache-sort-words (words-list) "对 WORDS-LIST 排序,词频大的排在前面. 排序使用 `pyim-dcache-icode2count' 中记录的词频信息" (sort words-list #'(lambda (a b) (let ((a (car (split-string a ":"))) (b (car (split-string b ":")))) (> (or (gethash a pyim-dcache-iword2count) 0) (or (gethash b pyim-dcache-iword2count) 0))))))
(defun pyim-dcache-get-path (variable) "获取保存 VARIABLE 取值的文件的路径." (when (symbolp variable) (concat (file-name-as-directory pyim-dcache-directory) (symbol-name variable))))
(defun pyim-dcache-init-variables () "初始化 dcache 缓存相关变量." (pyim-dcache-set-variable 'pyim-dcache-code2word) (pyim-dcache-set-variable 'pyim-dcache-word2count) (pyim-dcache-set-variable 'pyim-dcache-word2code) (pyim-dcache-set-variable 'pyim-dcache-shortcode2word) (pyim-dcache-set-variable 'pyim-dcache-icode2word) (pyim-dcache-set-variable 'pyim-dcache-iword2count) (pyim-dcache-set-variable 'pyim-dcache-ishortcode2word))
(defun pyim-dcache-set-variable (variable &optional force-restore fallback-value) "设置变量. 如果 VARIABLE 的值为 nil, 则使用 ‘pyim-dcache-directory’ 中对应文件的内容来设置 VARIABLE 变量,FORCE-RESTORE 设置为 t 时,强制恢复,变量原来的值将丢失。 如果获取的变量值为 nil 时,将 VARIABLE 的值设置为 FALLBACK-VALUE ." (when (or force-restore (not (symbol-value variable))) (let ((file (concat (file-name-as-directory pyim-dcache-directory) (symbol-name variable)))) (set variable (or (pyim-dcache-get-value-from-file file) fallback-value (make-hash-table :test #'equal))))))
(defun pyim-dcache-get-value-from-file (file) "读取保存到 FILE 里面的 value." (when (file-exists-p file) (with-temp-buffer (insert-file-contents file) (eval (read (current-buffer))))))
(defun pyim-dcache-save-variable (variable) "将 VARIABLE 变量的取值保存到 `pyim-dcache-directory' 中对应文件中." (let ((file (concat (file-name-as-directory pyim-dcache-directory) (symbol-name variable))) (value (symbol-value variable))) (pyim-dcache-save-value-to-file value file)))
(defun pyim-dcache-save-value-to-file (value file) "将 VALUE 保存到 FILE 文件中." (when value (with-temp-buffer (insert ";; Auto generated by `pyim-dcache-save-variable-to-file', don't edit it by hand!\n") (insert (format ";; Build time: %s\n\n" (current-time-string))) (insert (prin1-to-string value)) (insert "\n\n") (insert ";; Local Variables:\n") (insert ";; coding: utf-8-unix\n") (insert ";; End:") (make-directory (file-name-directory file) t) (write-file file))))
(defun pyim-dcache-generate-dcache-file (dict-files dcache-file) "读取词库文件列表:DICT-FILES, 生成一个词库缓冲文件 DCACHE-FILE." (let ((hashtable (make-hash-table :size 1000000 :test #'equal))) (dolist (file dict-files) (with-temp-buffer (let ((coding-system-for-read 'utf-8-unix)) (insert-file-contents file)) (goto-char (point-min)) (forward-line 1) (while (not (eobp)) (let ((code (pyim-code-at-point)) (content (pyim-line-content))) (when (and code content) (puthash code (delete-dups `(,@content ,@(gethash code hashtable))) hashtable))) (forward-line 1)))) (pyim-dcache-save-value-to-file hashtable dcache-file) hashtable))
(defun pyim-dcache-generate-word2code-dcache-file (dcache file) "从 DCACHE 生成一个 word -> code 的反向查询表. DCACHE 是一个 code -> words 的 hashtable. 并将生成的表保存到 FILE 中." (when (hash-table-p dcache) (let ((hashtable (make-hash-table :size 1000000 :test #'equal))) (maphash #'(lambda (code words) (unless (pyim-string-match-p "-" code) (dolist (word words) (let ((value (gethash word hashtable))) (puthash word (if value `(,code ,@value) (list code)) hashtable))))) dcache) (pyim-dcache-save-value-to-file hashtable file))))
(defun pyim-code-at-point () "Get code in the current line." (save-excursion (beginning-of-line) (if (re-search-forward "[ \t:]" (line-end-position) t) (buffer-substring-no-properties (line-beginning-position) (1- (point))))))
(defun pyim-line-content (&optional seperaters) "用 SEPERATERS 分解当前行,所有参数传递给 ‘split-string’ 函数." (let* ((begin (line-beginning-position)) (end (line-end-position)) (items (cdr (split-string (buffer-substring-no-properties begin end) seperaters)))) items))
(defun pyim-dcache-save-caches () "保存 dcache. 将 `pyim-dcache-icode2word' 和 `pyim-dcache-iword2count' 取值 保存到它们对应的文件中. 这个函数默认作为 `kill-emacs-hook' 使用。" (interactive) (pyim-dcache-save-variable 'pyim-dcache-icode2word) (pyim-dcache-save-variable 'pyim-dcache-iword2count) t)
(define-obsolete-function-alias
'pyim-personal-dcache-export 'pyim-dcache-export-personal-dcache)
(defun pyim-dcache-export-personal-dcache () "将 ‘pyim-dcache-icode2word’ 导出为 pyim 词库文件." (interactive) (let ((file (read-file-name "将个人缓存中的词条导出到文件:"))) (with-temp-buffer (insert ";;; -*- coding: utf-8-unix -*-\n") (maphash #'(lambda (key value) (insert (concat key " " (mapconcat #'identity value " ") "\n"))) pyim-dcache-icode2word) (write-file file))))
2.5.2 从词库中搜索中文词条
当词库文件加载完成后, pyim 就可以从词库缓存中搜索某个 code 对应的中文词条了,这个工作由函数 `pyim-dcache-get' 完成。
(defun pyim-dcache-get (code &optional dcache-list) (let ((dcache-list (or (if (listp dcache-list) dcache-list (list dcache-list)) (list pyim-dcache-icode2word pyim-dcache-code2word))) result) (dolist (cache dcache-list) (let ((value (gethash code cache))) (when value (setq result (append result value))))) `(,@result ,@(pyim-pinyin2cchar-get code t t))))
(defun pyim-string-match-p (regexp string &optional start) (and (stringp regexp) (stringp string) (string-match-p regexp string start)))
(defun pyim-pinyin-build-regexp (pinyin &optional match-beginning first-equal all-equal) "从 `pinyin' 构建一个 regexp,用于搜索联想词, 比如:ni-hao-si-j --> ^ni-hao[a-z]*-si[a-z]*-j[a-z]* , when `first-equal' set to `t' --> ^ni[a-z]*-hao[a-z]*-si[a-z]*-j[a-z]* , when `first-equal' set to `nil'" (when (and pinyin (stringp pinyin)) (let ((pinyin-list (split-string pinyin "-")) (count 0)) (concat (if match-beginning "^" "") (mapconcat #'(lambda (x) (setq count (+ count 1)) (if (or (not first-equal) (> count 1)) (if all-equal x (concat x "[a-z]*")) x)) pinyin-list "-")))))
2.5.3 保存词条,删除词条以及调整词条位置
(defmacro pyim-dcache-put (cache code &rest body) (declare (indent 0)) (let ((key (make-symbol "key")) (table (make-symbol "table")) (new-value (make-symbol "new-value"))) `(let* ((,key ,code) (,table ,cache) (orig-value (gethash ,key ,table)) ,new-value) (setq ,new-value (progn ,@body)) (unless (equal orig-value ,new-value) (puthash ,key ,new-value ,table)))))
(defun pyim-create-or-rearrange-word (word &optional rearrange-word) "将中文词条 `word' 添加拼音后,保存到 `pyim-dcache-icode2word' 中, 词条 `word' 会追加到已有词条的后面。 `pyim-create-or-rearrange-word' 会调用 `pyim-hanzi2pinyin' 来获取中文词条 的拼音 code。 BUG:无法有效的处理多音字。" (when (and (> (length word) 0) (< (length word) 11) ;十个汉字以上的词条,加到个人词库里面用处不大,忽略。 (not (pyim-string-match-p "\\CC" word))) (let* ((pinyins (pyim-hanzi2pinyin word nil "-" t nil t))) ;使用了多音字校正 ;; 保存对应词条的词频 (when (> (length word) 0) (pyim-dcache-put pyim-dcache-iword2count word (+ (or orig-value 0) 1))) ;; 添加词条到个人缓存 (dolist (py pinyins) (unless (pyim-string-match-p "[^ a-z-]" py) (pyim-dcache-put pyim-dcache-icode2word py (if rearrange-word (pyim-list-merge word orig-value) (pyim-list-merge orig-value word))))))))
(defun pyim-list-merge (a b) "Join list A and B to a new list, then delete dups." (let ((a (if (listp a) a (list a))) (b (if (listp b) b (list b)))) (delete-dups `(,@a ,@b))))
(defun pyim-cstring-at-point (&optional number) "获取光标一个中文字符串,字符数量为:`number'" (save-excursion (let* ((point (point)) (begin (- point number)) (begin (if (> begin 0) begin (point-min))) (string (buffer-substring-no-properties point begin))) (when (and (stringp string) (= (length string) number) (not (pyim-string-match-p "\\CC" string))) string))))
(defun pyim-create-word-at-point (&optional number silent) "将光标前字符数为 `number' 的中文字符串添加到个人词库中 当 `silent' 设置为 t 是,不显示提醒信息。" (let* ((string (pyim-cstring-at-point (or number 2)))) (when string (pyim-create-or-rearrange-word string) (unless silent (message "将词条: \"%s\" 加入 personal 缓冲。" string)))))
(defun pyim-create-2cchar-word-at-point () "将光标前2个中文字符组成的字符串加入个人词库。" (interactive) (pyim-create-word-at-point 2))
(defun pyim-create-3cchar-word-at-point () "将光标前3个中文字符组成的字符串加入个人词库。" (interactive) (pyim-create-word-at-point 3))
(defun pyim-create-4cchar-word-at-point () "将光标前4个中文字符组成的字符串加入个人词库。" (interactive) (pyim-create-word-at-point 4))
2.5.3.1 删词功能
(defun pyim-create-word-from-selection () "Add the selected text as a Chinese word into the personal dictionary." (interactive) (when (region-active-p) (let ((string (buffer-substring-no-properties (region-beginning) (region-end)))) (if (> (length string) 6) (error "词条太长") (if (not (string-match-p "^\\cc+\\'" string)) (error "不是纯中文字符串") (pyim-create-or-rearrange-word string) (message "将词条: %S 插入 personal file。" string))))))
(defun pyim-search-word-code () "选择词条,然后反查它的 code. 这个功能对五笔用户有用。" (interactive) (when (region-active-p) (let ((string (buffer-substring-no-properties (region-beginning) (region-end))) code) (if (not (string-match-p "^\\cc+\\'" string)) (error "不是纯中文字符串") (setq code (gethash string pyim-dcache-word2code)) (if code (message "%S -> %S " string code) (message "没有找到 %S 对应的编码。" string))))))
(defun pyim-delete-word () "将高亮选择的词条从 `pyim-dcache-icode2word' 中删除。" (interactive) (if mark-active (let ((string (buffer-substring-no-properties (region-beginning) (region-end)))) (when (and (< (length string) 6) (> (length string) 0)) (pyim-delete-word-1 string) (message "将词条: %S 从 personal 缓冲中删除。" string))) (message "请首先高亮选择需要删除的词条。")))
(defun pyim-delete-word-1 (word) "将中文词条 `word' 从 `pyim-dcache-icode2word' 中删除" (let* ((pinyins (pyim-hanzi2pinyin word nil "-" t)) (pinyins-szm (mapcar #'(lambda (pinyin) (mapconcat #'(lambda (x) (substring x 0 1)) (split-string pinyin "-") "-")) pinyins))) (dolist (pinyin pinyins) (unless (pyim-string-match-p "[^ a-z-]" pinyin) (pyim-dcache-put pyim-dcache-icode2word pinyin (remove word orig-value)))) (dolist (pinyin pinyins-szm) (unless (pyim-string-match-p "[^ a-z-]" pinyin) (pyim-dcache-put pyim-dcache-icode2word pinyin (remove word orig-value))))))
2.6 生成 `pyim-entered-code' 并插入 `pyim-dagger-str'
2.6.1 生成拼音字符串 `pyim-entered-code'
pyim 使用函数 `pyim-start' 启动输入法的时候,会将变量 `input-method-function' 设置为 `pyim-input-method' ,这个变量会影响 `read-event' 的行为。
当输入字符时,`read-event' 会被调用,`read-event' 调用的过程中,会执行 `pyim-input-method' 这个函数。`pyim-input-method' 又调用函数 `pyim-start-translation'
`pyim-start-translation' 这个函数较复杂,作许多低层工作,但它的一个重要流程是:
- 使用函数 `read-key-sequence' 得到 key-sequence
- 使用函数 `lookup-key' 查询 pyim-mode-map 中,上述 key-sequence 对应的命令。
- 如果查询得到的命令是 'pyim-self-insert-command' 时, `pyim-start-translation' 会调用这个函数。
`pyim-self-insert-command' 这个函数的核心工作就是将用户输入的字符,组合成 code 字符串并保存到变量 `pyim-entered-code' 中。
中英文输入模式切换功能也是在 'pyim-self-insert-command' 中实现。
这个部份的代码涉及许多 emacs 低层函数,相对复杂,不容易理解,有兴趣的朋友可以参考:
- `quail-input-method' 相关函数。
- elisp 手册相关章节:
- Invoking the Input Method
- Input Methods
- Miscellaneous Event Input Features
- Reading One Event
2.6.2 在待输入 buffer 中插入 `pyim-dagger-str'
`pyim-self-insert-command' 会调用 `pyim-handle-entered-code' 来处理 `pyim-entered-code',并相应的得到对应的 `pyim-dagger-str',然后, `pyim-start-translation' 返回 `pyim-dagger-str' 的取值。
在 `pyim-input-method' 函数内部,`pyim-start-translation' 返回值分解为 event list。
最后,emacs 低层函数 read-event 将这个 list 插入待输入buffer 。
(defun pyim-input-method (key-or-string) (if (or buffer-read-only overriding-terminal-local-map overriding-local-map) (if (characterp key-or-string) (list key-or-string) (mapcar 'identity key-or-string)) ;; (message "call with key: %S" key-or-string) (pyim-dagger-setup-overlay) (with-silent-modifications (unwind-protect (let ((input-string (pyim-start-translation key-or-string))) ;; (message "input-string: %s" input-string) (when (and (stringp input-string) (> (length input-string) 0)) (if input-method-exit-on-first-char (list (aref input-string 0)) (mapcar 'identity input-string)))) (pyim-dagger-delete-overlay)))))
(defun pyim-start-translation (key-or-string) "Start translation of the typed character KEY by pyim. Return the input string." ;; Check the possibility of translating KEY. ;; If KEY is nil, we can anyway start translation. (if (or (integerp key-or-string) (stringp key-or-string) (null key-or-string)) ;; OK, we can start translation. (let* ((echo-keystrokes 0) (help-char nil) (overriding-terminal-local-map pyim-mode-map) (generated-events nil) (input-method-function nil) ;; Quail package 用这个变量来控制是否在 buffer 中 ;; 插入 dagger string, pyim *强制* 将其设置为 nil (input-method-use-echo-area nil) (modified-p (buffer-modified-p)) key str last-command-event last-command this-command) (if (integerp key-or-string) (setq key key-or-string) (setq key (string-to-char (substring key-or-string -1))) (setq str (substring key-or-string 0 -1))) (setq pyim-dagger-str "" pyim-entered-code (or str "") pyim-translating t) (when key (setq unread-command-events (cons key unread-command-events))) (while pyim-translating (set-buffer-modified-p modified-p) (let* ((keyseq (read-key-sequence nil nil nil t)) (cmd (lookup-key pyim-mode-map keyseq))) ;; (message "key: %s, cmd:%s\nlcmd: %s, lcmdv: %s, tcmd: %s" ;; key cmd last-command last-command-event this-command) (if (if key (commandp cmd) (eq cmd 'pyim-self-insert-command)) (progn ;; (message "keyseq: %s" keyseq) (setq last-command-event (aref keyseq (1- (length keyseq))) last-command this-command this-command cmd) (setq key t) (condition-case-unless-debug err (call-interactively cmd) (error (message "pyim 出现错误: %s , 开启 debug-on-error 后可以了解详细情况。" (cdr err)) (beep)))) ;; KEYSEQ is not defined in the translation keymap. ;; Let's return the event(s) to the caller. (setq unread-command-events (string-to-list (this-single-command-raw-keys))) ;; (message "unread-command-events: %s" unread-command-events) (pyim-terminate-translation)))) ;; (message "return: %s" pyim-dagger-str) pyim-dagger-str) ;; Since KEY doesn't start any translation, just return it. ;; But translate KEY if necessary. (char-to-string key-or-string)))
(defun pyim-auto-switch-english-input-p () "判断是否 *根据环境自动切换* 为英文输入模式,这个函数处理变量: `pyim-english-input-switch-functions'" (let* ((func-or-list pyim-english-input-switch-functions)) (and (cl-some #'(lambda (x) (if (functionp x) (funcall x) nil)) (cond ((functionp func-or-list) (list func-or-list)) ((listp func-or-list) func-or-list) (t nil))) (setq current-input-method-title (concat pyim-title (if pyim-input-ascii "-英文" "-AU英"))))))
(defun pyim-input-chinese-p () "确定 pyim 是否启动中文输入模式" (let* ((scheme-name pyim-default-scheme) (first-chars (pyim-scheme-get-option scheme-name :first-chars)) (rest-chars (pyim-scheme-get-option scheme-name :rest-chars))) (and (or pyim-force-input-chinese (and (not pyim-input-ascii) (not (pyim-auto-switch-english-input-p)))) (if (pyim-string-emptyp pyim-entered-code) (member last-command-event (mapcar 'identity first-chars)) (member last-command-event (mapcar 'identity rest-chars))) (setq current-input-method-title pyim-title))))
(defun pyim-string-emptyp (str) (not (string< "" str)))
(defun pyim-self-insert-command () "如果在 pyim-first-char 列表中,则查找相应的词条,否则停止转换,插入对应的字符" (interactive "*") ;; (message "%s" (current-buffer)) (if (pyim-input-chinese-p) (progn (setq pyim-entered-code (concat pyim-entered-code (char-to-string last-command-event))) (pyim-handle-entered-code)) (pyim-dagger-append (pyim-translate last-command-event)) (pyim-terminate-translation)))
(defun pyim-terminate-translation () "Terminate the translation of the current key." (setq pyim-translating nil) (pyim-dagger-delete-string) (setq pyim-current-choices nil) (when (and (eq pyim-page-tooltip 'pos-tip) (pyim-tooltip-pos-tip-usable-p)) (pos-tip-hide)))
2.7 处理拼音 code 字符串 `pyim-entered-code'
2.7.1 拼音字符串 -> 待选词列表
从一个拼音字符串获取其待选词列表,大致可以分成3个步骤:
分解这个拼音字符串,得到一个拼音列表。
woaimeinv -> (("w" . "o") ("" . "ai") ("m" . "ei") ("n" . "v"))将拼音列表排列组合,得到多个词语的拼音,并用列表表示。
(("p" . "in") ("y" . "in") ("sh" . "") ("r" . "")) => ("pin-yin" ;; 完整的拼音 ("p-y-sh" ("p" . "in") ("y" . "in") ("sh" . "")) ;; 不完整的拼音 ("p-y-sh-r" ("p" . "in") ("y" . "in") ("sh" . "") ("r" . "")) ;; 不完整的拼音 )- 递归的查询上述多个词语拼音,将得到的结果合并为待选词列表。
2.7.1.1 分解拼音字符串
拼音字符串操作主要做两方面的工作:
- 将拼音字符串分解为拼音列表。
- 将拼音列表合并成拼音字符串。
在这之前,pyim 定义了三个变量:
- 声母表: `pyim-pinyin-shen-mu'
- 韵母表:`pyim-pinyin-yun-mu'
- 有效韵母表: `pyim-pinyin-valid-yun-mu'
pyim 使用函数 `pyim-code-split' 将拼音字符串分解为一个由声母和韵母组成的拼音列表,比如:
(pyim-code-split "woaimeinv" 'quanpin)
结果为:
((("w" . "o") ("" . "ai") ("m" . "ei") ("n" . "v")))
这个过程通过递归的调用 `pyim-pinyin-get-charpy' 来实现,整个过程类似用菜刀切黄瓜片,将一个拼音字符串逐渐切开。比如:
(pyim-pinyin-get-charpy "woaimeinv")
结果为:
(("w" . "o") . "aimeinv")
一个完整的递归过程类似:
"woaimeinv"
(("w" . "o") . "aimeinv")
(("w" . "o") ("" . "ai") . "meinv")
(("w" . "o") ("" . "ai") ("m" . "ei" ) . "nv")
(("w" . "o") ("" . "ai") ("m" . "ei" ) ("n" . "v"))
`pyim-pinyin-get-charpy' 由两个基本函数配合实现:
- pyim-pinyin-get-sm 从一个拼音字符串中提出第一个声母
- pyim-pinyin-get-ym 从一个拼音字符串中提出第一个韵母
(pyim-pinyin-get-sm "woaimeinv")
结果为:
("w" . "oaimeinv")
(pyim-pinyin-get-ym "oaimeinv")
结果为:
("o" . "aimeinv")
当用户输入一个错误的拼音时,`pyim-code-split' 会产生一个声母为空而韵母又不正确的拼音列表 ,比如:
(pyim-code-split "ua" 'quanpin)
结果为:
((("" . "ua")))
这种错误可以使用函数 `pyim-scode-validp' 来检测。
(list (pyim-scode-validp (car (pyim-code-split "ua" 'quanpin)) 'quanpin)
(pyim-scode-validp (car (pyim-code-split "a" 'quanpin)) 'quanpin)
(pyim-scode-validp (car (pyim-code-split "wa" 'quanpin)) 'quanpin)
(pyim-scode-validp (car (pyim-code-split "wua" 'quanpin)) 'quanpin))
结果为:
(nil t t t)
pyim 使用函数 `pyim-scode-join' 将一个 scode (splited code) 合并为一个 code 字符串,这个可以认为是 `pyim-code-split' 的反向操作。构建得到的 code 字符串用于搜索词条。
(pyim-scode-join '(("w" . "o") ("" . "ai") ("m" . "ei") ("n" . "v")) 'quanpin)
结果为:
"wo-ai-mei-nv"
最后: `pyim-code-user-divide-pos' 和 `pyim-code-restore-user-divide' 用来处理隔音符,比如: xi'an
将汉字的拼音分成声母和其它
(defun pyim-pinyin-get-sm (py) "从一个拼音字符串中提出第一个声母。" (when (and py (string< "" py)) (let (shenmu yunmu len) (if (< (length py) 2) (if (member py pyim-pinyin-shen-mu) (cons py "") (cons "" py)) (setq shenmu (substring py 0 2)) (if (member shenmu pyim-pinyin-shen-mu) (setq py (substring py 2)) (setq shenmu (substring py 0 1)) (if (member shenmu pyim-pinyin-shen-mu) (setq py (substring py 1)) (setq shenmu ""))) (cons shenmu py)))))
(defun pyim-pinyin-get-ym (py) "从一个拼音字符串中提出第一个韵母" (when (and py (string< "" py)) (let (yunmu len) (setq len (min (length py) 5)) (setq yunmu (substring py 0 len)) (while (and (not (member yunmu pyim-pinyin-yun-mu)) (> len 0)) (setq yunmu (substring py 0 (setq len (1- len))))) (setq py (substring py len)) (if (and (string< "" py) (not (member (substring py 0 1) pyim-pinyin-shen-mu)) (member (substring yunmu -1) pyim-pinyin-shen-mu) (member (substring yunmu 0 -1) pyim-pinyin-yun-mu) (not (and (member (substring yunmu -1) '("n" "g")) (or (string= (substring py 0 1) "o") (string= (substring py 0 (min (length py) 2)) "er"))))) (setq py (concat (substring yunmu -1) py) yunmu (substring yunmu 0 -1))) (cons yunmu py))))
(defun pyim-pinyin-get-charpy (py) "分解一个拼音字符串成声母和韵母。" (when (and py (string< "" py)) (let* ((sm (pyim-pinyin-get-sm py)) (ym (pyim-pinyin-get-ym (cdr sm))) (charpys (mapcar #'(lambda (x) (concat (car x) (cdr x))) (pyim-spinyin-find-fuzzy-1 (cons (car sm) (car ym)))))) (if (or (null ym) ;如果韵母为空 (and (string< "" (car ym)) (not (cl-some #'(lambda (charpy) (or (pyim-pinyin2cchar-get charpy t) (pyim-dcache-get charpy))) charpys)))) (cons sm "") (cons (cons (car sm) (car ym)) (cdr ym))))))
处理输入的拼音
(defun pyim-scheme-get (scheme-name) "获取名称为 `scheme-name' 的输入法方案。" (assoc scheme-name pyim-schemes))
(defun pyim-scheme-get-option (scheme-name option) "获取名称为 `scheme-name' 的输入法方案,并提取其属性 `option' 。" (let ((scheme (pyim-scheme-get scheme-name))) (when scheme (plist-get (cdr scheme) option))))
(defun pyim-code-split (code &optional scheme-name) "按照 `scheme-name' 对应的输入法方案,把一个 code 字符串分解为一个由 scode 组成的列表,类似: 1. pinyin: (((\"n\" . \"i\") (\"h\" . \"ao\"))) 注意: 不同的输入法,scode 的结构也是不一样的。" (let ((class (pyim-scheme-get-option scheme-name :class))) (when class (funcall (intern (format "pyim-code-split-%S-code" class)) code scheme-name))))
(defun pyim-code-split-quanpin-code (py &optional -) "把一个拼音字符串 `py' 分解成 spinyin-list (由声母和韵母组成的复杂列表), 优先处理含有 ' 的位置。" (when (and py (string< "" py)) (pyim-spinyin-find-fuzzy (list (apply 'append (mapcar #'(lambda (p) (let (chpy spinyin) (setq p (replace-regexp-in-string "[ -]" "" p)) (while (when (string< "" p) (setq chpy (pyim-pinyin-get-charpy p)) (setq spinyin (append spinyin (list (car chpy)))) (setq p (cdr chpy)))) spinyin)) (split-string py "'")))))))
"nihc" -> (((\"n\" . \"i\") (\"h\" . \"ao\")))
(defun pyim-code-split-shuangpin-code (str &optional scheme-name) "把一个双拼字符串分解成一个声母和韵母组成的复杂列表。" (let ((keymaps (pyim-scheme-get-option scheme-name :keymaps)) (list (string-to-list (replace-regexp-in-string "-" "" str))) results) (while list (let* ((sp-sm (pop list)) (sp-ym (pop list)) (sp-sm (when sp-sm (char-to-string sp-sm))) (sp-ym (when sp-ym (char-to-string sp-ym))) (sm (nth 1 (assoc sp-sm keymaps))) (ym (cdr (cdr (assoc sp-ym keymaps))))) (push (mapcar #'(lambda (x) (let* ((y (concat sp-sm (or sp-ym " "))) (z (cadr (assoc y keymaps)))) (if z (cons "" z) (cons sm x)))) (or ym (list ""))) results))) (pyim-spinyin-find-fuzzy (pyim-permutate-list (nreverse results)))))
(defun pyim-code-split-xingma-code (code &optional -) "这个函数只是对 code 做了一点简单的包装,实际并不真正的 *分解* code, 用于五笔等基于形码的输入法, 比如: \"aaaa\" -> ((\"aaaa\"))" (list (list code)))
(defun pyim-spinyin-find-fuzzy (spinyin-list) "用于处理模糊音的函数。" (let (fuzzy-spinyin-list result1 result2) (dolist (spinyin spinyin-list) (setq fuzzy-spinyin-list (pyim-permutate-list (mapcar 'pyim-spinyin-find-fuzzy-1 spinyin))) (push (car fuzzy-spinyin-list) result1) (setq result2 (append result2 (cdr fuzzy-spinyin-list)))) (append result1 result2)))
(defun pyim-spinyin-find-fuzzy-1 (pycons) "Find all fuzzy pinyins, for example: (\"f\" . \"en\") -> ((\"f\" . \"en\") (\"f\" . \"eng\"))" (cl-labels ((find-list (str list) (let (result) (dolist (x list) (when (member str x) (setq list nil) (setq result (delete-dups `(,str ,@(cl-copy-list x)))))) (or result (list str))))) (let* ((fuzzy-alist pyim-fuzzy-pinyin-alist) (sm-list (find-list (car pycons) fuzzy-alist)) (ym-list (find-list (cdr pycons) fuzzy-alist)) result) (dolist (a sm-list) (dolist (b ym-list) (push (cons a b) result))) (reverse result))))
(defun pyim-scode-validp (scode scheme-name) "检测一个 scode 是否正确。" (let ((class (pyim-scheme-get-option scheme-name :class))) (cond ((member class '(quanpin shuangpin)) (pyim-scode-spinyin-validp scode)) (t t))))
(defun pyim-scode-spinyin-validp (spinyin) "检查 `spinyin' 是否声母为空且韵母又不正确。" (let ((valid t) py) (while (progn (setq py (car spinyin)) (if (and (not (string< "" (car py))) (not (member (cdr py) pyim-pinyin-valid-yun-mu))) (setq valid nil) (setq spinyin (cdr spinyin))))) valid))
(defun pyim-code-user-divide-pos (code) "检测 `code' 中用户分割的位置,也就是'的位置,主要用于拼音输入法。" (setq code (replace-regexp-in-string "-" "" code)) (let (poslist (start 0)) (while (string-match "'" code start) (setq start (match-end 0)) (setq poslist (append poslist (list (match-beginning 0))))) poslist))
(defun pyim-code-restore-user-divide (code pos) "按检测出的用户分解的位置,重新设置 code,主要用于拼音输入法。" (let ((i 0) (shift 0) cur) (setq cur (car pos) pos (cdr pos)) (while (and cur (< i (length code))) (if (= (aref code i) ?-) (if (= i (+ cur shift)) (progn (aset code i ?') (setq cur (car pos) pos (cdr pos))) (setq shift (1+ shift)))) (setq i (1+ i))) (if cur (setq code (concat code "'"))) ; the last char is `'' code))
(defun pyim-scode-join (scode scheme-name &optional as-search-key shou-zi-mu) "按照 `scheme' 对应的输入法方案,将一个 scode (splited code) 重新合并为 code 字符串,用于搜索。" (let ((class (pyim-scheme-get-option scheme-name :class))) (when class (funcall (intern (format "pyim-scode-join-%S-scode" class)) scode scheme-name as-search-key shou-zi-mu))))
(defun pyim-scode-join-quanpin-scode (spinyin scheme-name &optional as-search-key shou-zi-mu) "把一个 `spinyin' (splited pinyin) 合并为一个全拼字符串,当 `shou-zi-mu' 设置为 t 时,生成拼音首字母字符串,比如 p-y。" (mapconcat 'identity (mapcar #'(lambda (w) (let ((py (concat (car w) (cdr w)))) (if shou-zi-mu (substring py 0 1) py))) spinyin) "-"))
(defun pyim-scode-join-shuangpin-scode (spinyin scheme-name &optional as-search-key shou-zi-mu) "把一个 `spinyin' (splited pinyin) 合并为一个双拼字符串,当 `shou-zi-mu' 设置为 t 时,生成双拼首字母字符串,比如 p-y。" (if as-search-key ;; 双拼使用全拼输入法的词库,所以搜索 dcache 用的 key 要使用全拼 (pyim-scode-join-quanpin-scode spinyin scheme-name as-search-key shou-zi-mu) (when scheme-name (let ((keymaps (pyim-scheme-get-option scheme-name :keymaps))) (mapconcat 'identity (mapcar #'(lambda (w) (let ((sm (car w)) (ym (cdr w))) (if (equal sm "") (car (rassoc (list ym) keymaps)) (concat (cl-some #'(lambda (x) (when (equal sm (nth 1 x)) (car x))) keymaps) (unless shou-zi-mu (cl-some #'(lambda (x) (when (or (equal ym (nth 2 x)) (equal ym (nth 3 x))) (car x))) keymaps)))))) spinyin) "-")))))
(defun pyim-scode-join-xingma-scode (scode scheme-name &optional as-search-key shou-zi-mu) "把一个 `scode' (splited code) 合并为一个 code 字符串, 用于五笔等基于形码的输入法。 比如: (\"aaaa\") --> \"aaaa\" 用于在 dagger 中显示。 `-> \".aaaa\" 用于搜索词库。" (when scheme-name (let ((code-prefix (pyim-scheme-get-option scheme-name :code-prefix)) (n (pyim-scheme-get-option scheme-name :code-split-length))) (if as-search-key (concat (or code-prefix "") (car scode)) (car scode)))))
2.7.1.2 获得词语拼音并进一步查询得到备选词列表
(defun pyim-choices-get (scode-list scheme-name) "根据 `scode-list', 得到可能的词组和汉字。" ;; scode-list 可以包含多个 scode, 从而得到多个子候选词列表,如何将多个 *子候选词列表* 合理的合并, ;; 是一个比较麻烦的事情的事情。 注:这个地方需要进一步得改进。 (let* (personal-words common-words jianpin-words znabc-words pinyin-chars xingma-words) (dolist (scode scode-list) (setq personal-words (append personal-words (car (pyim-choices-get-personal-dcache-words scode scheme-name)))) (setq common-words (append common-words (car (pyim-choices-get-common-dcache-words scode scheme-name)))) (setq pinyin-chars (append pinyin-chars (car (pyim-choices-get-pinyin-chars scode scheme-name)))) (setq xingma-words (append xingma-words (car (pyim-choices-get-xingma-words scode scheme-name))))) ;; Pinyin shouzimu similar words (let ((words (pyim-choices-get-jianpin-words (car scode-list) scheme-name))) (setq jianpin-words (car (cdr words)))) ;; Pinyin znabc-style similar words (let ((words (pyim-choices-get-znabc-words (car scode-list) scheme-name))) (setq znabc-words (car (cdr words)))) ;; Debug (when pyim-debug (princ (list :scode-list scode-list :personal-words personal-words :common-words common-words :jianpin-words jianpin-words :znabc-words znabc-words :pinyin-chars pinyin-chars))) (delete-dups (delq nil `(,@personal-words ,@common-words ,@jianpin-words ,@znabc-words ,@pinyin-chars ,@xingma-words)))))
(defun pyim-choices-get-znabc-words (spinyin scheme-name) ;; 将输入的拼音按照声母和韵母打散,得到尽可能多的拼音组合, ;; 查询这些拼音组合,得到的词条做为联想词。 (when (member 'znabc-words pyim-backends) (let ((class (pyim-scheme-get-option scheme-name :class))) (when (member class '(quanpin shuangpin)) (list nil (pyim-possible-words (pyim-possible-words-py spinyin)))))))
(defun pyim-choices-get-jianpin-words (spinyin scheme-name) ;; 如果输入 "ni-hao" ,搜索 code 为 "n-h" 的词条做为联想词。 ;; 搜索首字母得到的联想词太多,这里限制联想词要大于两个汉字并且只搜索 ;; 个人文件。 (when (member 'jianpin-words pyim-backends) (let ((class (pyim-scheme-get-option scheme-name :class))) (when (and (> (length spinyin) 1) (member class '(quanpin shuangpin))) (let ((pyabbrev (pyim-scode-join spinyin scheme-name t t))) (list nil (pyim-dcache-get pyabbrev pyim-dcache-ishortcode2word)))))))
(defun pyim-choices-get-pinyin-chars (spinyin scheme-name) (when (member 'pinyin-chars pyim-backends) (let ((class (pyim-scheme-get-option scheme-name :class))) (when (member class '(quanpin shuangpin)) (list (pyim-dcache-get (concat (caar spinyin) (cdar spinyin))) nil)))))
(defun pyim-split-string-by-number (str n &optional reverse) (let (output) (while str (if (< (length str) n) (progn (push str output) (setq str nil)) (push (substring str 0 n) output) (setq str (substring str n)))) (if reverse output (nreverse output))))
(defun pyim-choices-get-xingma-words (scode scheme-name) (when (member 'xingma-words pyim-backends) (let ((class (pyim-scheme-get-option scheme-name :class))) (when (member class '(xingma)) (let* ((code-prefix (pyim-scheme-get-option scheme-name :code-prefix)) (code (pyim-scode-join-xingma-scode scode scheme-name)) (n (pyim-scheme-get-option scheme-name :code-split-length)) (output (pyim-split-string-by-number code n t)) (output1 (car output)) (output2 (reverse (cdr output))) str) (when output2 (setq str (mapconcat #'(lambda (code) (car (pyim-dcache-get (concat code-prefix code)))) output2 ""))) (list (remove "" (or (mapcar #'(lambda (x) (concat str x)) (pyim-dcache-get (concat code-prefix output1) (list pyim-dcache-code2word pyim-dcache-shortcode2word))) (list str))) nil))))))
(defun pyim-choices-get-personal-dcache-words (scode scheme-name) (when (member 'personal-dcache-words pyim-backends) (let ((code (pyim-scode-join scode scheme-name t))) (list (pyim-dcache-get code (list pyim-dcache-icode2word pyim-dcache-ishortcode2word)) nil))))
(defun pyim-choices-get-common-dcache-words (scode scheme-name) (when (member 'common-dcache-words pyim-backends) (let ((code (pyim-scode-join scode scheme-name t))) (list (pyim-dcache-get code (list pyim-dcache-code2word pyim-dcache-shortcode2word)) nil))))
(defun pyim-flatten-list (my-list) (cond ((null my-list) nil) ((atom my-list) (list my-list)) (t (append (pyim-flatten-list (car my-list)) (pyim-flatten-list (cdr my-list))))))
(defun pyim-possible-words (wordspy) "根据拼音得到可能的词组。例如: (pyim-possible-words '((\"p-y\" (\"p\" . \"in\") (\"y\" . \"\")))) => (\"拼音\" \"贫铀\" \"聘用\") " (let (words) (dolist (word (reverse wordspy)) (if (listp word) (setq words (append words (pyim-dcache-get (car word)))) (setq words (append words (pyim-dcache-get word))))) words))
(defun pyim-possible-words-py (spinyin) "所有可能的词组拼音。从第一个字开始,每个字断开形成一个拼音。如果是 完整拼音,则给出完整的拼音,如果是给出声母,则为一个 CONS CELL,CAR 是 拼音,CDR 是拼音列表。例如: (setq foo-spinyin (pyim-code-split \"pin-yin-sh-r\" 'quanpin)) => ((\"p\" . \"in\") (\"y\" . \"in\") (\"sh\" . \"\") (\"r\" . \"\")) (pyim-possible-words-py foo-spinyin) => (\"pin-yin\" (\"p-y-sh\" (\"p\" . \"in\") (\"y\" . \"in\") (\"sh\" . \"\")) (\"p-y-sh-r\" (\"p\" . \"in\") (\"y\" . \"in\") (\"sh\" . \"\") (\"r\" . \"\"))) " (let (pys fullpy smpy wordlist (full t)) (if (string< "" (cdar spinyin)) (setq fullpy (concat (caar spinyin) (cdar spinyin)) smpy (pyim-essential-py (car spinyin))) (setq smpy (caar spinyin) full nil)) (setq wordlist (list (car spinyin))) (dolist (py (cdr spinyin)) (setq wordlist (append wordlist (list py))) (if (and full (string< "" (cdr py))) (setq fullpy (concat fullpy "-" (car py) (cdr py)) smpy (concat smpy "-" (pyim-essential-py py)) pys (append pys (list fullpy))) (setq full nil smpy (concat smpy "-" (pyim-essential-py py)) pys (append pys (list (cons smpy wordlist)))))) ;; (message "%s: %s" pys wordlist)) pys))
(defun pyim-essential-py (py) "一个拼音中的主要部分,如果有声母返回声母,否则返回韵母" (if (string< "" (car py)) (car py) (cdr py)))
2.7.2 核心函数:拼音字符串处理函数
`pyim-handle-entered-code' 这个函数是一个重要的核心函数,其大致工作流程为:
- 查询拼音字符串 `pyim-entered-code' 得到: 待选词列表 `pyim-current-choices' 和 当前选择的词条 `pyim-entered-code'
- 显示备选词条和选择备选词等待用户选择。
(defun pyim-handle-entered-code () (let ((scheme-name pyim-default-scheme) (str pyim-entered-code)) (setq pyim-scode-list (pyim-code-split str scheme-name) pyim-code-position 0) (unless (and (pyim-scode-validp (car pyim-scode-list) scheme-name) (progn (setq pyim-entered-code (pyim-code-restore-user-divide (pyim-scode-join (car pyim-scode-list) scheme-name) (pyim-code-user-divide-pos str))) (setq pyim-current-choices (list (delete-dups (pyim-choices-get pyim-scode-list scheme-name)))) (when (car pyim-current-choices) (setq pyim-current-pos 1) (pyim-dagger-refresh) (pyim-page-refresh) t))) (setq pyim-current-choices (list (list (format "%s" (replace-regexp-in-string "-" " " pyim-entered-code))))) (setq pyim-current-pos 1) (pyim-dagger-refresh) (pyim-page-refresh))))
2.8 处理当前需要插入 buffer 的 dagger 字符串: `pyim-dagger-str'
pyim 使用变量 `pyim-dagger-str' 保存需要在 buffer 光标处插入的字符串。
处理 `pyim-dagger-str' 的代码分散在多个函数中,可以按照下面的方式分类:
- 英文字符串:pyim 没有找到相应的候选词时(比如:用户输入错误的拼音),`pyim-dagger-str' 的值与 `pyim-entered-code' 大致相同。相关代码很简单,分散在 `pyim-handle-entered-code' 或者 `pyim-dagger-append' 等相关函数。
汉字或者拼音和汉字的混合:当 pyim 找到相应的候选词条时, `pyim-dagger-str' 的值可以是完全的中文词条,比如:
你好或者中文词条+拼音的混合新式,比如:
你好bj这部份代码相对复杂,使用 `pyim-update-current-key' 专门处理。
pyim 会使用 emacs overlay 机制在待输入buffer 光标处高亮显示 `pyim-dagger-str',让用户快速了解当前输入的字符串,具体方式是:
- 在 `pyim-input-method' 中调用 `pyim-dagger-setup-overlay' 创建 overlay ,并使用变量 `pyim-dagger-overlay' 保存,创建时将 overlay 的 face 属性设置为 `pyim-dagger-face' ,用户可以使用这个变量来自定义 face。
- 使用函数 `pyim-dagger-show' 高亮显示 `pyim-dagger-str'
- 清除光标处原来的字符串。
- 插入 `pyim-dagger-str'
- 使用 `move-overlay' 函数调整变量 `pyim-dagger-overlay' 中保存的 overlay,让其符合新插入的字符串。
- 在 `pyim-input-method' 中调用 `pyim-dagger-delete-overlay' ,删除 `pyim-dagger-overlay' 中保存的 overlay,这个函数同时也删除了 overlay 中包含的文本 `pyim-dagger-str'。
真正在待输入buffer 插入 `pyim-dagger-str' 字符串的函数是 `read-event',具体见 `pyim-input-method' 相关说明。
(defun pyim-dagger-setup-overlay () (let ((pos (point))) (if (overlayp pyim-dagger-overlay) (move-overlay pyim-dagger-overlay pos pos) (setq pyim-dagger-overlay (make-overlay pos pos)) (if input-method-highlight-flag (overlay-put pyim-dagger-overlay 'face 'pyim-dagger-face)))))
(defun pyim-dagger-delete-overlay () (if (and (overlayp pyim-dagger-overlay) (overlay-start pyim-dagger-overlay)) (delete-overlay pyim-dagger-overlay)))
(defun pyim-dagger-append (str) "Append STR to `pyim-dagger-str'" (setq pyim-dagger-str (concat pyim-dagger-str str)))
(defun pyim-dagger-refresh () "更新 `pyim-dagger-str' 的值。" (let* ((end (pyim-page-end)) (start (1- (pyim-page-start))) (choices (car pyim-current-choices)) (choice (pyim-subseq choices start end)) (pos (1- (min pyim-current-pos (length choices)))) rest) (setq pyim-dagger-str (concat (substring pyim-dagger-str 0 pyim-code-position) (pyim-choice (nth pos choices)))) (setq rest (mapconcat #'(lambda (py) (concat (car py) (cdr py))) (nthcdr (length pyim-dagger-str) (car pyim-scode-list)) "'")) (if (string< "" rest) (setq pyim-dagger-str (concat pyim-dagger-str rest))) (unless enable-multibyte-characters (setq pyim-entered-code nil pyim-dagger-str nil) (error "Can't input characters in current unibyte buffer")) ;; Delete old dagger string. (pyim-dagger-delete-string) ;; Insert new dagger string. (insert pyim-dagger-str) ;; Hightlight new dagger string. (move-overlay pyim-dagger-overlay (overlay-start pyim-dagger-overlay) (point))))
(defun pyim-dagger-delete-string () "删除已经插入 buffer 的 dagger 字符串。" (if (overlay-start pyim-dagger-overlay) (delete-region (overlay-start pyim-dagger-overlay) (overlay-end pyim-dagger-overlay))))
2.9 显示和选择备选词条
2.9.1 构建词条菜单字符串
pyim 内建两种方式显示选词框:
- 使用 `pyim-minibuffer-message' 函数在 minibuffer 中显示选词框。
- 使用 `pyim-tooltip-show' 函数在光标处创建一个 tooltip 来显示选词框。
两种方式的基本原理相同:通过待选词列表构建为一个字符串,然后显示这个字符串。用户可以根据这个字符串的提示,来执行相应的动作,比如按空格确认当前选择的词条或者按数字选择这个数字对应的词条。比如:
"1. 你好 2. 倪皓 3. 你 4.泥 ..."
pyim 使用 `pyim-current-choices' 来保存待选词列表,我们以 "nihao" 对应的 `pyim-current-choices' 的值为例,来说明选词框相关的操作函数。
("你好" "倪皓" "泥" "你" "呢" "拟" "逆" "腻" "妮" "怩" "溺" "尼" "禰" "齯" "麑" "鲵" "蜺" "衵" "薿" "旎" "睨" "铌" "昵" "匿" "倪" "霓" "暱" "柅" "猊" "郳" "輗" "坭" "惄" "堄" "儗" "伲" "祢" "慝")
选词框的格式通过变量 `pyim-page-style' 来控制。
待选词列表一般都很长,不可能在一行中完全显示,所以 pyim 使用了 page 的概念,比如,上面的 “nihao” 的待选词列表就可以逻辑的分成5页:
("你好" 倪皓" "泥" "你" "呢" "拟" "逆" "腻" "妮" ;第1页
"怩" "溺" "尼" "禰" "齯" "麑" "鲵" "蜺" "衵" ;第2页
"薿" "旎" "睨" "铌" "昵" "匿" "倪" "霓" "暱" ;第3页
"柅" "猊" "郳" "輗" "坭" "惄" "堄" "儗" "伲" ;第4页
"祢" "慝" ;第5页)
用户可以使用变量 `pyim-page-length' 自定义每一页显示词条的数量,默认设置为9。
`pyim-current-pos' 的取值以及 `pyim-page-length' 的设定值,共同决定了 pyim 需要显示哪一页,我们以一个表格来表示上述待选词列表:
| 第1页 | "你好" | 倪皓" | "泥" | "你" | "呢" | "拟" | "逆" | "腻" | "妮" |
| 第2页 | "怩" | "溺" | "尼" | "禰" | "齯" | "麑" | "鲵" | "蜺" | "衵" |
| 第3页 | -B- "薿" | "旎" | -A-"睨" | "铌" | "昵" | "匿" | "倪" | "霓" | -E- "暱" |
| 第4页 | "柅" | "猊" | "郳" | "輗" | "坭" | "惄" | "堄" | "儗" | "伲" |
| 第5页 | "祢" | "慝" |
假设 `pyim-current-pos' 为 A 所在的位置。那么:
- 函数 `pyim-page-current-page' 返回值为3, 说明当前 page 为第3页。
- 函数 `pyim-page-total-page' 返回值为5,说明 page 共有5页。
- 函数 `pyim-page-start' 返回 B 所在的位置。
- 函数 `pyim-page-end' 返回 E 所在的位置。
函数 `pyim-page-refresh' 用于刷新显示 page 它会从 `pyim-current-choices' 中提取一个 sublist:
("薿" "旎" "睨" "铌" "昵" "匿" "倪" "霓" "暱")这个 sublist 的起点为 `pyim-page-start' 的返回值,终点为 `pyim-page-end' 的返回值。然后使用这个 sublist 来构建类似下面的字符串,并保存到一个 hashtable 的 :words 关键字对应的位置,这个 hastable 最终会做为参数传递给 `pyim-page-style' 相关的函数,用于生成 page。
"1. 薿 2.旎 3.睨 4.铌 5.昵 6.匿 7.倪 8.霓 9.暱"
`pyim-page-next-page' 这个命令用来翻页,其原理是:改变 `pyim-current-pos'的取值,假设一次只翻一页,那么这个函数所做的工作就是:
- 首先将 `pyim-current-pos' 增加 `pyim-page-length' ,确保其指定的位置在下一页。
- 然后将 `pyim-current-pos' 的值设定为 `pyim-page-start' 的返回值,确保 `pyim-current-pos' 的取值为下一页第一个词条的位置。
最后调用 `pyim-page-refresh' 来重新刷新页面。
page format
(defun pyim-subseq (list from &optional to) (if (null to) (nthcdr from list) (butlast (nthcdr from list) (- (length list) to))))
(defun pyim-mod (x y) "like `mod', but when result is 0, return Y" (let ((base (mod x y))) (if (= base 0) y base)))
(defun pyim-choice (choice) (let ((output (if (consp choice) (car choice) choice))) (if (stringp output) (car (split-string output ":")) output)))
(defun pyim-page-current-page () (1+ (/ (1- pyim-current-pos) pyim-page-length)))
(defun pyim-page-total-page () (1+ (/ (1- (length (car pyim-current-choices))) pyim-page-length)))
(defun pyim-page-start () "计算当前所在页的第一个词条的位置" (let ((pos (min (length (car pyim-current-choices)) pyim-current-pos))) (1+ (- pos (pyim-mod pos pyim-page-length)))))
(defun pyim-page-end (&optional finish) "计算当前所在页的最后一个词条的位置,如果 pyim-current-choices 用 完,则检查是否有补全。如果 FINISH 为 non-nil,说明,补全已经用完了" (let* ((whole (length (car pyim-current-choices))) (len pyim-page-length) (pos pyim-current-pos) (last (+ (- pos (pyim-mod pos len)) len))) (if (< last whole) last (if finish whole (pyim-page-end t)))))
(defun pyim-page-format-key-string (code) "这个函数用于生成 page 中显示的 code。" (let* ((scheme-name pyim-default-scheme) (class (pyim-scheme-get-option scheme-name :class)) (code-maximum-length (pyim-scheme-get-option scheme-name :code-split-length))) (cond ((memq class '(xingma)) (mapconcat #'identity (pyim-split-string-by-number code code-maximum-length) " ")) (t (replace-regexp-in-string "-" " " code)))))
(defun pyim-page-refresh (&optional hightlight-current) "按当前位置,生成候选词条" (let* ((end (pyim-page-end)) (start (1- (pyim-page-start))) (choices (car pyim-current-choices)) (choice (mapcar #'(lambda (x) (if (stringp x) (replace-regexp-in-string ":" "" x) x)) (pyim-subseq choices start end))) (pos (- (min pyim-current-pos (length choices)) start)) (page-info (make-hash-table)) (i 0)) (puthash :key (pyim-page-format-key-string pyim-entered-code) page-info) (puthash :current-page (pyim-page-current-page) page-info) (puthash :total-page (pyim-page-total-page) page-info) (puthash :words (mapconcat 'identity (mapcar (lambda (c) (setq i (1+ i)) (let (str) (setq str (if (consp c) (concat (car c) (cdr c)) c)) ;; 高亮当前选择的词条,用于 `pyim-page-next-word' (if (and hightlight-current (= i pos)) (format "%d[%s]" i (propertize str 'face 'pyim-page-selected-word-face)) (format "%d.%s " i str)))) choice) "") page-info) ;; Show page. (when (and (null unread-command-events) (null unread-post-input-method-events)) (if (eq (selected-window) (minibuffer-window)) ;; Show the guidance in the next line of the currrent ;; minibuffer. (pyim-minibuffer-message (format " [%s]\n%s" current-input-method-title (gethash :words page-info))) ;; Show the guidance in echo area without logging. (let ((message-log-max nil)) (if pyim-page-tooltip (pyim-tooltip-show (let ((func (intern (format "pyim-page-style-%S-style" pyim-page-style)))) (if (functionp func) (funcall func page-info) (pyim-page-style-two-lines-style page-info))) (overlay-start pyim-dagger-overlay)) (message "%s" (pyim-page-style-minibuffer-style page-info))))))))
(defun pyim-page-next-page (arg) (interactive "p") (if (= (length pyim-entered-code) 0) (progn (pyim-dagger-append (pyim-translate last-command-event)) (pyim-terminate-translation)) (let ((new (+ pyim-current-pos (* pyim-page-length arg) 1))) (setq pyim-current-pos (if (> new 0) new 1) pyim-current-pos (pyim-page-start)) (pyim-dagger-refresh) (pyim-page-refresh))))
(defun pyim-page-previous-page (arg) (interactive "p") (pyim-page-next-page (- arg)))
(defun pyim-page-next-word (arg) (interactive "p") (if (= (length pyim-entered-code) 0) (progn (pyim-dagger-append (pyim-translate last-command-event)) (pyim-terminate-translation)) (let ((new (+ pyim-current-pos arg))) (setq pyim-current-pos (if (> new 0) new 1)) (pyim-dagger-refresh) (pyim-page-refresh t))))
(defun pyim-page-previous-word (arg) (interactive "p") (pyim-page-next-word (- arg)))
(defun pyim-page-style-two-lines-style (page-info) "将 page-info 格式化为类似下面格式的字符串,这个字符串将在 tooltip 选词框中显示。 +----------------------------+ | ni hao [1/9] | | 1.你好 2.你号 ... | +----------------------------+" (format "=> %s [%s/%s]: \n%s" (gethash :key page-info) (gethash :current-page page-info) (gethash :total-page page-info) (gethash :words page-info)))
(defun pyim-page-style-one-line-style (page-info) "将 page-info 格式化为类似下面格式的字符串,这个字符串将在 tooltip 选词框中显示。 +-----------------------------------+ | [ni hao]: 1.你好 2.你号 ... (1/9) | +-----------------------------------+" (format "[%s]: %s(%s/%s)" (replace-regexp-in-string " +" "" (gethash :key page-info)) (gethash :words page-info) (gethash :current-page page-info) (gethash :total-page page-info)))
(defun pyim-page-style-vertical-style (page-info) "将 page-info 格式化为类似下面格式的字符串,这个字符串将在 tooltip 选词框中显示。 +--------------+ | ni hao [1/9] | | 1.你好 | | 2.你号 ... | +--------------+" (format "=> %s [%s/%s]: \n%s" (gethash :key page-info) (gethash :current-page page-info) (gethash :total-page page-info) (replace-regexp-in-string "]" "]\n" (replace-regexp-in-string " +" "\n" (gethash :words page-info)))))
(defun pyim-page-style-minibuffer-style (page-info) "将 page-info 格式化为类似下面格式的字符串,这个字符串 将在 minibuffer 中显示。 +----------------------------------+ | ni hao [1/9] 1.你好 2.你号 ... | +----------------------------------+" (format "%s [%s/%s]: %s" (gethash :key page-info) (gethash :current-page page-info) (gethash :total-page page-info) (gethash :words page-info)))
(defun pyim-tooltip-show (string position) "在 `position' 位置,使用 pos-tip 或者 popup 显示字符串 `string' 。" (let ((frame (window-frame (selected-window))) (length (* pyim-page-length 10)) (tooltip pyim-page-tooltip) (pos-tip-usable-p (pyim-tooltip-pos-tip-usable-p))) (cond ((or (eq tooltip t) (eq tooltip 'popup) (and (eq tooltip 'pos-tip) (not pos-tip-usable-p))) (popup-tip string :point position :margin 1)) ((and pos-tip-usable-p (eq tooltip 'pos-tip)) (pos-tip-show-no-propertize string nil position nil 15 (round (* (pos-tip-tooltip-width length (frame-char-width frame)) pyim-page-tooltip-width-adjustment)) nil nil nil 35)) ((eq tooltip 'minibuffer) (let ((max-mini-window-height (+ pyim-page-length 2))) (message string))) (t (error "`pyim-page-tooltip' 设置不对,请重新设置。")))))
(defun pyim-minibuffer-message (string) (message nil) (let ((point-max (point-max)) (inhibit-quit t)) (save-excursion (goto-char point-max) (insert string)) (sit-for 1000000) (delete-region point-max (point-max)) (when quit-flag (setq quit-flag nil unread-command-events '(7)))))
(defun pyim-tooltip-pos-tip-usable-p () "测试当前环境下 pos-tip 是否可用。" (not (or noninteractive emacs-basic-display (not (display-graphic-p)) (not (fboundp 'x-show-tip)))))
2.9.2 选择备选词
(defun pyim-page-select-word () "从选词框中选择当前词条。" (interactive) (if (null (car pyim-current-choices)) ; 如果没有选项,输入空格 (progn (setq pyim-dagger-str (pyim-translate last-command-event)) (pyim-terminate-translation)) (let ((str (pyim-choice (nth (1- pyim-current-pos) (car pyim-current-choices)))) scode-list) (pyim-create-or-rearrange-word str t) (setq pyim-code-position (+ pyim-code-position (length str))) (if (>= pyim-code-position (length (car pyim-scode-list))) ; 如果是最后一个,检查 ; 是不是在文件中,没有的话,创 ; 建这个词 (progn (if (not (member pyim-dagger-str (car pyim-current-choices))) (pyim-create-or-rearrange-word pyim-dagger-str)) (pyim-terminate-translation) ;; pyim 使用这个 hook 来处理联想词。 (run-hooks 'pyim-page-select-finish-hook)) (setq scode-list (delete-dups (mapcar #'(lambda (scode) (nthcdr pyim-code-position scode)) pyim-scode-list))) (setq pyim-current-choices (list (pyim-choices-get scode-list pyim-default-scheme)) pyim-current-pos 1) (pyim-dagger-refresh) (pyim-page-refresh)))))
(defun pyim-page-select-word-by-number (&optional n) "使用数字编号来选择对应的词条。" (interactive) (if (car pyim-current-choices) (let ((index (if (numberp n) (- n 1) (- last-command-event ?1))) (end (pyim-page-end))) (if (> (+ index (pyim-page-start)) end) (pyim-page-refresh) (setq pyim-current-pos (+ pyim-current-pos index)) (setq pyim-dagger-str (concat (substring pyim-dagger-str 0 pyim-code-position) (pyim-choice (nth (1- pyim-current-pos) (car pyim-current-choices))))) (pyim-page-select-word))) (pyim-dagger-append (char-to-string last-command-event)) (pyim-terminate-translation)))
2.10 处理标点符号
常用的标点符号数量不多,所以 pyim 没有使用文件而是使用一个变量 `pyim-punctuation-dict' 来设置标点符号对应表,这个变量是一个 alist 列表。
pyim 在运行过程中调用函数 `pyim-translate' 进行标点符号格式的转换。
(defun pyim-translate-get-trigger-char () "检查 `pyim-translate-trigger-char' 是否为一个合理的 trigger char 。 pyim 的 translate-trigger-char 要占用一个键位,为了防止用户 自定义设置与输入法冲突,这里需要检查一下这个键位设置的是否合理, 如果不合理,就返回输入法默认设定。" (let* ((user-trigger-char pyim-translate-trigger-char) (user-trigger-char (if (characterp user-trigger-char) (char-to-string user-trigger-char) (when (= (length user-trigger-char) 1) user-trigger-char))) (first-char (pyim-scheme-get-option pyim-default-scheme :first-chars)) (prefer-trigger-chars (pyim-scheme-get-option pyim-default-scheme :prefer-trigger-chars))) (if (pyim-string-match-p user-trigger-char first-char) (progn ;; (message "注意:pyim-translate-trigger-char 设置和当前输入法冲突,使用推荐设置:\"%s\"" ;; prefer-trigger-chars) prefer-trigger-chars) user-trigger-char)))
(defun pyim-translate (char) (let* ((str (char-to-string char)) ;; 注意:`str' 是 *待输入* 的字符对应的字符串。 (str-before-1 (pyim-char-before-to-string 0)) (str-before-2 (pyim-char-before-to-string 1)) (str-before-3 (pyim-char-before-to-string 2)) (str-before-4 (pyim-char-before-to-string 3)) ;; 从标点词库中搜索与 `str' 对应的标点列表。 (punc-list (assoc str pyim-punctuation-dict)) ;; 从标点词库中搜索与 `str-before-1' 对应的标点列表。 (punc-list-before-1 (cl-some (lambda (x) (when (member str-before-1 x) x)) pyim-punctuation-dict)) ;; `str-before-1' 在其对应的标点列表中的位置。 (punc-posit-before-1 (cl-position str-before-1 punc-list-before-1 :test #'equal)) (trigger-str (pyim-translate-get-trigger-char))) (cond ;; 空格之前的字符什么也不输入。 ((< char ? ) "") ;; 这个部份与标点符号处理无关,主要用来快速保存用户自定义词条。 ;; 比如:在一个中文字符串后输入 2v,可以将光标前两个中文字符 ;; 组成的字符串,保存到个人词库。 ((and (member (char-before) (number-sequence ?2 ?9)) (pyim-string-match-p "\\cc" str-before-2) (equal str trigger-str)) (delete-char -1) (pyim-create-word-at-point (string-to-number str-before-1)) "") ;; 光标前面的字符为中文字符时,按 v 清洗当前行的内容。 ((and (not (numberp punc-posit-before-1)) (pyim-string-match-p "\\cc" str-before-1) (equal str trigger-str)) (funcall pyim-wash-function) "") ;; 关闭标点转换功能时,只插入英文标点。 ((not (pyim-punctuation-full-width-p)) str) ;; 当前字符属于 `pyim-punctuation-escape-list'时, ;; 插入英文标点。 ((member (char-before) pyim-punctuation-escape-list) str) ;; 当 `pyim-punctuation-half-width-functions' 中 ;; 任意一个函数返回值为 t 时,插入英文标点。 ((cl-some #'(lambda (x) (if (functionp x) (funcall x char) nil)) pyim-punctuation-half-width-functions) str) ;; 当光标前面为英文标点时, 按 `pyim-translate-trigger-char' ;; 对应的字符后, 自动将其转换为对应的中文标点。 ((and (numberp punc-posit-before-1) (= punc-posit-before-1 0) (equal str trigger-str)) (pyim-punctuation-translate-last-n-puncts 'full-width) "") ;; 当光标前面为中文标点时, 按 `pyim-translate-trigger-char' ;; 对应的字符后, 自动将其转换为对应的英文标点。 ((and (numberp punc-posit-before-1) (> punc-posit-before-1 0) (equal str trigger-str)) (pyim-punctuation-translate-last-n-puncts 'half-width) "") ;; 正常输入标点符号。 (punc-list (pyim-punctuation-return-proper-punct punc-list)) ;; 当输入的字符不是标点符号时,原样插入。 (t str))))
(defun pyim-char-before-to-string (num) "得到光标前第 `num' 个字符,并将其转换为字符串。" (let* ((point (point)) (point-before (- point num))) (when (and (> point-before 0) (char-before point-before)) (char-to-string (char-before point-before)))))
(defun pyim-wash-current-line-function () "清理当前行的内容,比如:删除不必要的空格,等。" (interactive) (let* ((begin (line-beginning-position)) (end (point)) (string (buffer-substring-no-properties begin end)) new-string) (when (> (length string) 0) (delete-region begin end) (setq new-string (with-temp-buffer (insert string) (goto-char (point-min)) (while (re-search-forward "\\([,。;?!;、)】]\\) +\\([[:ascii:]]\\)" nil t) (replace-match (concat (match-string 1) (match-string 2)) nil t)) (goto-char (point-min)) (while (re-search-forward "\\([[:ascii:]]\\) +\\([(【]\\)" nil t) (replace-match (concat (match-string 1) (match-string 2)) nil t)) (goto-char (point-min)) (while (re-search-forward "\\([[:ascii:]]\\) +\\(\\cc\\)" nil t) (replace-match (concat (match-string 1) " " (match-string 2)) nil t)) (goto-char (point-min)) (while (re-search-forward "\\(\\cc\\) +\\([[:ascii:]]\\)" nil t) (replace-match (concat (match-string 1) " " (match-string 2)) nil t)) (buffer-string))) (insert new-string))))
当用户使用 org-mode 以及 markdown 等轻量级标记语言撰写文档时,常常需要输入数字列表,比如:
1. item1 2. item2 3. item3
在这种情况下,数字后面输入句号必须是半角句号而不是全角句号,pyim 调用 `pyim-translate' 时,会检测光标前面的字符,如果这个字符属于 `pyim-punctuation-escape-list' ,pyim 将输入半角标点,具体细节见:`pyim-translate'
输入标点的样式的改变(全角或者半角)受三个方面影响:
- 用户是否手动切换了标点样式?
2 用户是否手动切换到英文输入模式?
- pyim 是否根据环境自动切换到英文输入模式?
三方面的综合结果为: 只要当前的输入模式是英文输入模式,那么输入的标点符号必定是半角标点,如果当前输入模式是中文输入模式,那么,输入标点的样式用户可以使用 `pyim-punctuation-toggle' 手动控制,具体请参考 `pyim-punctuation-full-width-p'。
切换中英文标点符号
(defun pyim-punctuation-full-width-p () "判断是否需要切换到全角标点输入模式" (cl-case (car pyim-punctuation-translate-p) (yes t) (no nil) (auto ;; 如果用户手动或者根据环境自动切换为英文输入模式, ;; 那么标点符号也要切换为半角模式。 (and (not pyim-input-ascii) (not (pyim-auto-switch-english-input-p))))))
(defun pyim-punctuation-toggle () (interactive) (setq pyim-punctuation-translate-p `(,@(cdr pyim-punctuation-translate-p) ,(car pyim-punctuation-translate-p))) (message (cl-case (car pyim-punctuation-translate-p) (yes "开启全角标点输入模式。") (no "开启半角标点输入模式。") (auto "开启全半角标点自动转换模式。"))))
每次运行 `pyim-punctuation-toggle' 命令,都会调整变量 `pyim-punctuation-translate-p' 的取值,`pyim-translate' 根据 `pyim-punctuation-full-width-p' 函数的返回值,来决定是否转换标点符号:
- 当返回值为 'yes 时,`pyim-translate' 转换标点符号,从而输入全角标点。
- 当返回值为 'no 时,`pyim-translate' 忽略转换,从而输入半角标点。
- 当返回值为 'auto 时,根据中英文环境,自动切换。
用户也可以使用命令 `pyim-punctuation-translate-at-point' 来切换光标前标点符号的样式。
(defun pyim-punctuation-translate-at-point () "切换光标处标点的样式(全角 or 半角)。" (interactive) (let* ((current-char (char-to-string (preceding-char))) (punc-list (cl-some (lambda (x) (when (member current-char x) x)) pyim-punctuation-dict))) (when punc-list (delete-char -1) (if (equal current-char (car punc-list)) (insert (pyim-punctuation-return-proper-punct punc-list)) (insert (car punc-list))))))
(defun pyim-punctuation-translate-last-n-puncts (&optional punct-style) "将光标前面连续的n个标点符号进行全角/半角转换,当 `punct-style' 设置为 `full-width' 时, 所有的标点符号转换为全角符号,设置为 `half-width' 时,转换为半角符号。" (interactive) (let ((punc-list (pyim-flatten-list pyim-punctuation-dict)) (punct-style (or punct-style (intern (completing-read "将光标前的标点转换为" '("full-width" "half-width"))))) (count 0) number last-puncts result) (while count (let ((str (pyim-char-before-to-string count))) (if (member str punc-list) (progn (push str last-puncts) (setq count (+ count 1))) (setq number count) (setq count nil)))) ;; 删除旧的标点符号 (delete-char (- 0 number)) (dolist (punct last-puncts) (dolist (puncts pyim-punctuation-dict) (let ((position (cl-position punct puncts :test #'equal))) (when position (cond ((eq punct-style 'full-width) (if (= position 0) (push (pyim-punctuation-return-proper-punct puncts) result) (push punct result))) ((eq punct-style 'half-width) (if (= position 0) (push punct result) (push (car puncts) result)))))))) (insert (mapconcat #'identity (reverse result) ""))))
使用上述命令切换光标前标点符号的样式时,我们使用函数 `pyim-punctuation-return-proper-punct' 来处理成对的全角标点符号, 比如:
“”‘’
这个函数的参数是一个标点符号对应表,类似:
("." "。")
第一个元素为半角标点,第二个和第三个元素(如果有)为对应的全角标点。
(list (pyim-punctuation-return-proper-punct '("'" "‘" "’"))
(pyim-punctuation-return-proper-punct '("'" "‘" "’")))
结果为:
("’" "‘")
简单来说,定义这个函数的目的是为了实现类似的功能:如果第一次输入的标点是:(‘)时,那么下一次输入的标点就是(’)。
处理标点符号
(defun pyim-punctuation-return-proper-punct (punc-list &optional before) "返回合适的标点符号,`punc-list'为标点符号列表,其格式类似: `(\",\" \",\") 或者:`(\"'\" \"‘\" \"’\") 当 `before' 为 t 时,只返回切换之前的结果,这个用来获取切换之前 的标点符号。" (let* ((str (car punc-list)) (punc (cdr punc-list)) (switch-p (cdr (assoc str pyim-punctuation-pair-status)))) (if (= (safe-length punc) 1) (car punc) (if before (setq switch-p (not switch-p)) (setf (cdr (assoc str pyim-punctuation-pair-status)) (not switch-p))) (if switch-p (car punc) (nth 1 punc)))))
函数 `pyim-punctuation-return-proper-punct' 内部,我们使用变量 `pyim-punctuation-pair-status' 来记录“成对”中文标点符号的状态。
2.11 处理特殊功能触发字符(单字符快捷键)
输入中文的时候,我们需要快速频繁的执行一些特定的命令,最直接的方法就是将上述命令绑定到一个容易按的快捷键上,但遗憾的是 emacs 大多数容易按的快捷键都名花有主了,甚至找一个 “Ctrl+单字符”的快捷键都不太容易,特殊功能触发字符,可以帮助我们实现“单字符”快捷键,类似 org-mode 的 speed key。
默认情况下,我们可以使用特殊功能触发字符执行下面两个操作:
快速切换中英文标点符号的样式:当光标前的字符是一个标点符号时,按"v"可以切换这个标点的样式。比如:光标在A处的时候,按 "v" 可以将A前面的全角逗号转换为半角逗号。
你好,-A-按 "v" 后
你好,-A-快速将光标前的词条添加到词库:当光标前的字符是中文字符时,按 "num" + "v" 可以将光标前 num 个中文汉字组成的词条添加到个人词频文件中,比如:当光标在A处时,按"4v"可以将“的红烧肉”这个词条加入个人词频文件,默认 num不超过9。
我爱吃美味的红烧肉-A-
值得注意的是,这种方式如果添加的功能太多,会造成许多潜在的冲突。
用户可以使用变量 `pyim-translate-trigger-char' 来设置触发字符,默认的触发字符是:"v", 选择这个字符的理由是:
- "v" 不是有效的声母,不会对中文输入造成太大的影响。
- "v" 字符很容易按。
pyim 使用函数 `pyim-translate' 来处理特殊功能触发字符。当待输入的字符是触发字符时,`pyim-translate' 根据光标前的字符的不同来调用不同的功能,具体见 `pyim-translate' :
2.12 与拼音输入相关的用户命令
2.12.1 删除拼音字符串最后一个字符
(defun pyim-delete-last-char () (interactive) (if (> (length pyim-entered-code) 1) (progn (setq pyim-entered-code (substring pyim-entered-code 0 -1)) (pyim-handle-entered-code)) (setq pyim-dagger-str "") (pyim-terminate-translation)))
2.12.2 删除拼音字符串最后一个拼音
(defun pyim-backward-kill-py () (interactive) (if (string-match "['-][^'-]+$" pyim-entered-code) (progn (setq pyim-entered-code (replace-match "" nil nil pyim-entered-code)) (pyim-handle-entered-code)) (setq pyim-entered-code "") (setq pyim-dagger-str "") (pyim-terminate-translation)))
2.12.3 将光标前的 code 字符串转换为中文
(defun pyim-convert-code-at-point () (interactive) (unless (equal input-method-function 'pyim-input-method) (toggle-input-method)) (let* ((case-fold-search nil) (pyim-force-input-chinese t) (string (if mark-active (buffer-substring-no-properties (region-beginning) (region-end)) (buffer-substring (point) (line-beginning-position)))) code length) (if (pyim-string-match-p "[[:punct:]]" (pyim-char-before-to-string 0)) ;; 当光标前的一个字符是标点符号时,半角/全角切换。 (call-interactively 'pyim-punctuation-translate-at-point) (and (string-match "[a-z'-]+ *$" string) (setq code (match-string 0 string)) (setq length (length code)) (setq code (replace-regexp-in-string " +" "" code))) (when (and length (> length 0)) (delete-char (- 0 length)) (insert (mapconcat #'char-to-string (pyim-input-method code) ""))))))
2.12.4 取消当前输入
(defun pyim-quit-clear () (interactive) (setq pyim-dagger-str "") (pyim-terminate-translation))
2.12.5 字母上屏
(defun pyim-quit-no-clear () (interactive) (setq pyim-dagger-str (replace-regexp-in-string "-" "" pyim-entered-code)) (pyim-terminate-translation))
2.12.6 pyim 取消激活
(defun pyim-inactivate () (interactive) (mapc 'kill-local-variable pyim-local-variable-list))
2.12.7 切换中英文输入模式
(defun pyim-toggle-input-ascii () "pyim 切换中英文输入模式。同时调整标点符号样式。" (interactive) (setq pyim-input-ascii (not pyim-input-ascii)))
2.12.8 为 isearch 添加拼音搜索功能
(define-obsolete-function-alias
'pyim-isearch-build-search-regexp 'pyim-cregexp-build)
(defun pyim-cregexp-build (pystr) "根据 str 构建一个中文 regexp, 用于 \"拼音搜索汉字\". 比如: \"nihao\" -> \"[你呢...][好号...] \\| nihao\"" (let* ((scheme-name pyim-default-scheme) (class (pyim-scheme-get-option scheme-name :class))) ;; 确保 pyim 词库加载 (pyim-dcache-init-variables) ;; pyim 暂时只支持全拼和双拼搜索 (when (not (member class '(quanpin shuangpin))) (setq scheme-name 'quanpin)) (if (or (pyim-string-match-p "[^a-z']+" pystr)) pystr (let* ((spinyin-list ;; Slowly operating, need to improve. (pyim-code-split pystr scheme-name)) (regexp-list (mapcar #'(lambda (spinyin) (pyim-cregexp-build-from-spinyin spinyin)) spinyin-list)) (regexp (when regexp-list (mapconcat #'identity (delq nil regexp-list) "\\|"))) (regexp (if (> (length regexp) 0) (concat pystr "\\|" regexp) pystr))) regexp))))
(define-obsolete-function-alias
'pyim-spinyin-build-cregexp 'pyim-cregexp-build-from-spinyin)
(defun pyim-cregexp-build-from-spinyin (spinyin &optional match-beginning first-equal all-equal) "从 SPINYIN 创建一个中文 regexp. 用这个中文 regexp 可以搜索到拼音匹配 SPINYIN 的中文字符串。" (let* ((spinyin (mapcar #'(lambda (x) (concat (car x) (cdr x))) spinyin)) (cchar-list (let ((n 0) results) (dolist (py spinyin) (push (mapconcat #'identity (pyim-pinyin2cchar-get py (or all-equal (and first-equal (= n 0)))) "") results) (setq n (+ 1 n))) (nreverse results))) (regexp (mapconcat #'(lambda (x) (when (pyim-string-match-p "\\cc" x) (format "[%s]" x))) cchar-list ""))) (unless (equal regexp "") (concat (if match-beginning "^" "") regexp))))
(defun pyim-isearch-search-fun () "这个函数为 isearch 相关命令添加中文拼音搜索功能, 做为 `isearch-search-fun' 函数的 advice 使用。" (funcall (lambda () `(lambda (string &optional bound noerror count) (if (pyim-string-match-p "[^a-z]+" string) (funcall (isearch-search-fun-default) string bound noerror count) (funcall (if ,isearch-forward 're-search-forward 're-search-backward) (pyim-cregexp-build string) bound noerror count))))))
(define-minor-mode pyim-isearch-mode "pyim isearch mode." :global t :group 'pyim :lighter " pyim-isearch" (if pyim-isearch-mode (progn (advice-add 'isearch-search-fun :override #'pyim-isearch-search-fun) (message "PYIM: `pyim-isearch-mode' 已经激活,激活后,一些 isearch 扩展包有可能失效。")) (advice-remove 'isearch-search-fun #'pyim-isearch-search-fun)))
2.13 让 forward/backward 支持中文
(defun pyim-forward-word (&optional arg) "向前移动 `arg' 英文或者中文词,向前移动时基于 *最长* 的词移动。" (interactive "P") (or arg (setq arg 1)) (dotimes (i arg) (let* ((words (pyim-cwords-at-point t)) (max-length (cl-reduce #'max (cons 0 (mapcar #'(lambda (word) (nth 2 word)) words)))) (max-length (max (or max-length 1) 1))) (forward-char max-length))))
(defun pyim-backward-word (&optional arg) "向后移动 `arg' 个英文或者中文词,向后移动时基于 *最长* 的词移动。" (interactive "P") (or arg (setq arg 1)) (dotimes (i arg) (let* ((words (pyim-cwords-at-point)) (max-length (cl-reduce #'max (cons 0 (mapcar #'(lambda (word) (nth 1 word)) words)))) (max-length (max (or max-length 1) 1))) (backward-char max-length))))
(defun pyim-cwords-at-point (&optional end-of-point) "获取光标当前的词条列表,当 `end-of-point' 设置为 t 时,获取光标后的词条列表。 词条列表的每一个元素都是列表,这些列表的第一个元素为词条,第二个元素为光标处到词条 头部的距离,第三个元素为光标处到词条尾部的距离。 其工作原理是: 1. 使用 `thing-at-point' 获取当前光标处的一个字符串,一般而言:英文会得到 一个单词,中文会得到一个句子。 2. 英文单词直接返回这个单词的列表。 3. 中文句子首先用 `pyim-cstring-split-to-list' 分词,然后根据光标在中文句子 中的位置,筛选出符合要求的中文词条。得到并返回 *一个* 或者 *多个* 词条 的列表。" ;; ;; 光标到词 光标到词 ;; 首的距离 尾的距离 ;; | | ;; 获取光标当前的词<I>条列表 -> (("的词" 2 0) ("词条" 1 1)) ;; (let* ((case-fold-search t) (current-pos (point)) (current-char (if end-of-point (string (following-char)) (string (preceding-char)))) (str (thing-at-point 'word t)) (str-length (length str)) (str-boundary (bounds-of-thing-at-point 'word)) (str-beginning-pos (when str-boundary (car str-boundary))) (str-end-pos (when str-boundary (cdr str-boundary))) (str-offset (when (and str-beginning-pos str-end-pos) (if (= current-pos str-end-pos) (1+ (- str-end-pos str-beginning-pos)) (1+ (- current-pos str-beginning-pos))))) str-offset-adjusted words-alist results) ;; 当字符串长度太长时, `pyim-cstring-split-to-list' ;; 的速度比较慢,这里确保待分词的字符串长度不超过10. (when (and str (not (pyim-string-match-p "\\CC" str))) (if (> str-offset 5) (progn (setq str-offset-adjusted 5) (setq str (substring str (- str-offset 5) (min (+ str-offset 5) str-length)))) (setq str-offset-adjusted str-offset) (setq str (substring str 0 (min 9 str-length))))) (cond ((and str (not (pyim-string-match-p "\\CC" str))) (setq words-alist (pyim-cstring-split-to-list str)) (dolist (word-list words-alist) (let ((word-begin (nth 1 word-list)) (word-end (nth 2 word-list))) (if (if end-of-point (and (< str-offset-adjusted word-end) (>= str-offset-adjusted word-begin)) (and (<= str-offset-adjusted word-end) (> str-offset-adjusted word-begin))) (push (list (car word-list) (- str-offset-adjusted word-begin) ;; 例如: ("你好" 1 1) (- word-end str-offset-adjusted)) results)))) (or results (list (if end-of-point (list current-char 0 1) (list current-char 1 0))))) (str (list (list str (- current-pos str-beginning-pos) (- str-end-pos current-pos)))))))
2.14 简单的中文分词功能
(defun pyim-cstring-split-to-list (chinese-string &optional max-word-length) "一个基于 pyim 的中文分词函数。这个函数可以将中文字符 串 `chinese-string' 分词,得到一个词条 alist,这个 alist 的元素 都是列表,其中第一个元素为分词得到的词条,第二个元素为词条相对于 字符串中的起始位置,第三个元素为结束位置。分词时,默认词条不超过 6个字符,用户可以通过 `max-word-length' 来自定义,但值得注意的是: 这个值设置越大,分词速度越慢。 注意事项: 1. 这个工具使用暴力匹配模式来分词,*不能检测出* pyim 词库中不存在 的中文词条。 2. 这个函数的分词速度比较慢,仅仅适用于中文短句的分词,不适用于 文章分词。根据评估,20个汉字组成的字符串需要大约0.3s, 40个 汉字消耗1s,随着字符串长度的增大消耗的时间呈几何倍数增加。" ;; (("天安" 5 7) ;; 我爱北京天安门 -> ("天安门" 5 8) ;; ("北京" 3 5) ;; ("我爱" 1 3)) (cl-labels ((get-possible-words-internal ;; 内部函数,功能类似: ;; ("a" "b" "c" "d") -> ("abcd" "abc" "ab") (my-list number) (cond ((< (length my-list) 2) nil) (t (append (let* ((str (mapconcat #'identity my-list "")) (length (length str))) (when (<= length (or max-word-length 6)) (list (list str number (+ number length))))) (get-possible-words-internal (reverse (cdr (reverse my-list))) number))))) (get-possible-words ;; 内部函数,功能类似: ;; ("a" "b" "c" "d") -> ("abcd" "abc" "ab" "bcd" "bc" "cd") (my-list number) (cond ((null my-list) nil) (t (append (get-possible-words-internal my-list number) (get-possible-words (cdr my-list) (1+ number))))))) ;; 如果 pyim 词库没有加载,加载 pyim 词库, ;; 确保 pyim-dcache-get 可以正常运行。 (pyim-dcache-init-variables) (let ((string-alist (get-possible-words (mapcar #'char-to-string (string-to-vector chinese-string)) 1)) words-list result) (dolist (string-list string-alist) (let ((pinyin-list (pyim-hanzi2pinyin (car string-list) nil "-" t))) (dolist (pinyin pinyin-list) (let ((words (pyim-dcache-get pinyin pyim-dcache-code2word))) ; 忽略个人词库可以提高速度 (dolist (word words) (when (equal word (car string-list)) (push string-list result))))))) result)))
(let ((str "医生随时都有可能被患者及其家属反咬一口")) (benchmark 1 '(pyim-cstring-split-to-list str)))
(let ((str "医生随时都有可能被患者及其家属反咬一口")) (pyim-cstring-split-to-list str))
(defun pyim-cstring-split-to-string (string &optional prefer-short-word separator max-word-length) "将一个中文字符串分词,并且在分词的位置插入空格或者自定义分隔符 `separator', 较长的词条优先使用,如果 `prefer-short-word' 设置为 t,则优先使用较短的词条。 最长词条默认不超过6个字符,用户可以通 `max-word-length' 来自定义词条的最大长度, 但值得注意的是,这个值设置越大,分词速度越慢。" (let ((string-list (if (pyim-string-match-p "\\CC" string) (split-string (replace-regexp-in-string "\\(\\CC+\\)" "@@@@\\1@@@@" string) "@@@@") (list string)))) (mapconcat #'(lambda (str) (when (> (length str) 0) (if (not (pyim-string-match-p "\\CC" str)) (pyim-cstring-split-to-string-1 str prefer-short-word separator max-word-length) (concat " " str " ")))) string-list "")))
(defun pyim-cstring-split-to-string-1 (chinese-string &optional prefer-short-word separator max-word-length) "`pyim-cstring-split-to-string' 内部函数。" (let ((str-length (length chinese-string)) (word-list (cl-delete-duplicates ;; 判断两个词条在字符串中的位置 ;; 是否冲突,如果冲突,仅保留一个, ;; 删除其它。 (pyim-cstring-split-to-list chinese-string max-word-length) :test #'(lambda (x1 x2) (let ((begin1 (nth 1 x1)) (begin2 (nth 1 x2)) (end1 (nth 2 x1)) (end2 (nth 2 x2))) (not (or (<= end1 begin2) (<= end2 begin1))))) :from-end prefer-short-word)) position-list result) ;; 提取词条相对于字符串的位置信息。 (dolist (word word-list) (push (nth 1 word) position-list) (push (nth 2 word) position-list)) ;; 将位置信息由小到大排序。 (setq position-list (cl-delete-duplicates (sort position-list #'<))) ;; 在分词的位置插入空格或者用户指定的分隔符。 (dotimes (i str-length) (when (member (1+ i) position-list) (push (or separator " ") result)) (push (substring chinese-string i (1+ i)) result)) (setq result (nreverse result)) (mapconcat #'identity result "")))
(defun pyim-cstring-split-buffer () "将一个 buffer 中的中文文章,进行分词操作。" (interactive) (message "分词开始!") (goto-char (point-min)) (while (not (eobp)) (let ((string (buffer-substring-no-properties (line-beginning-position) (line-end-position)))) (delete-region (line-beginning-position) (min (+ (line-end-position) 1) (point-max))) (insert (pyim-cstring-split-to-string string)) (insert "\n"))) (goto-char (point-min)) (message "分词完成!"))
2.15 汉字到拼音的转换工具
`pyim-hanzi2pinyin' 和 `pyim-hanzi2pinyin-simple' 可以将一个中文字符串转换为拼音字符串或者拼音列表,也可以将一个中文字符串转换为拼音首字母字符串或者首字母列表。
在转换的过程中,`pyim-hanzi2pinyin' 考虑多音字,所以适用于制作词库,pyim 使用这个函数来制作词库。而 `pyim-hanzi2pinyin-simple' 不考虑多音字,可以用于添加拼音索引。
例如:
(list (pyim-hanzi2pinyin "银行")
(pyim-hanzi2pinyin "银行" t)
(pyim-hanzi2pinyin "银行" nil "-")
(pyim-hanzi2pinyin "银行" nil "-" t)
(pyim-hanzi2pinyin "银行" t "-" t))
RESULTS:
("yinhang yinxing" "yh yx" "yin-hang yin-xing" ("yin-hang" "yin-xing") ("y-h" "y-x"))
(list (pyim-hanzi2pinyin-simple "行长")
(pyim-hanzi2pinyin-simple "行长" t)
(pyim-hanzi2pinyin-simple "行长" nil "-")
(pyim-hanzi2pinyin-simple "行长" nil "-" t)
(pyim-hanzi2pinyin-simple "行长" t "-" t))
RESULTS:
("hangchang" "hc" "hang-chang" ("hang-chang") ("h-c"))
`pyim-hanzi2pinyin' 函数使用 “排列组合” 函数 `pyim-permutate-list' 来处理多音字,这个函数所做工作类似:
(cl-prettyprint
(pyim-permutate-list
'(("a" "b")
("c" "d")
("e" "f" "g"))))
OUTPUT:
(("a" "c" "e")
("a" "c" "f")
("a" "c" "g")
("a" "d" "e")
("a" "d" "f")
("a" "d" "g")
("b" "c" "e")
("b" "c" "f")
("b" "c" "g")
("b" "d" "e")
("b" "d" "f")
("b" "d" "g"))
(defun pyim-hanzi2pinyin (string &optional shou-zi-mu separator return-list ignore-duo-yin-zi adjust-duo-yin-zi) "将汉字字符串转换为对应的拼音字符串, 如果 `shou-zi-mu' 设置为t,转换仅得到拼音 首字母字符串。当 `return-list' 设置为 t 时,返回一个拼音列表,这个列表包含词条的一个 或者多个拼音(词条包含多音字时);如果 `ignore-duo-yin-zi' 设置为t, 遇到多音字时, 只使用第一个拼音,其它拼音忽略;当 `adjust-duo-yin-zi' 设置为t时,pyim-hanzi2pinyin 会使用 pyim 已安装的词库来校正多音字,但这个功能有一定的限制: 1. pyim 普通词库中不存在的词条不能较正 2. 多音字校正速度比较慢,实时转换会产生卡顿。 BUG: 当 `string' 中包含其它标点符号,并且设置 `separator' 时,结果会包含多余的连接符: 比如: '你=好' --> 'ni-=-hao'" (if (not (pyim-string-match-p "\\cc" string)) (if return-list (list string) string) (let (string-list pinyins-list pinyins-list-permutated pinyins-list-adjusted) ;; 将汉字字符串转换为字符list,英文原样输出。 ;; 比如: “Hello银行” -> ("Hello" "银" "行") (setq string-list (if (pyim-string-match-p "\\CC" string) ;; 处理中英文混合的情况 (split-string (replace-regexp-in-string "\\(\\cc\\)" "@@@@\\1@@@@" string) "@@@@") ;; 如果词条只包含中文,使用`string-to-vector' ;; 这样处理速度比较快。 (string-to-vector string))) ;; 将上述汉字字符串里面的所有汉字转换为与之对应的拼音list。 ;; 比如: ("Hello" "银" "行") -> (("Hello") ("yin") ("hang" "xing")) (mapc #'(lambda (str) ;; `string-to-vector' 得到的是 char vector, 需要将其转换为 string。 (when (numberp str) (setq str (char-to-string str))) (cond ((> (length str) 1) (push (list str) pinyins-list)) ((and (> (length str) 0) (pyim-string-match-p "\\cc" str)) (push (or (pyim-cchar2pinyin-get (string-to-char str)) (list str)) pinyins-list)) ((> (length str) 0) (push (list str) pinyins-list)))) string-list) (setq pinyins-list (nreverse pinyins-list)) ;; 通过排列组合的方式, 重排 pinyins-list。 ;; 比如:(("Hello") ("yin") ("hang" "xing")) -> (("Hello" "yin" "hang") ("Hello" "yin" "xing")) (setq pinyins-list-permutated (pyim-permutate-list2 pinyins-list)) ;; 使用 pyim 的安装的词库来校正多音字。 (when adjust-duo-yin-zi ;; 确保 pyim 词库加载 (pyim-dcache-init-variables) (dolist (pinyin-list pinyins-list-permutated) (let* ((py-str (mapconcat #'identity pinyin-list "-")) (words-from-dicts ;; pyim-buffer-list 中第一个 buffer 对应的是个人词库文件 ;; 个人词库文件中的词条,极有可能存在 *多音字污染*。 ;; 这是由 pyim 保存词条的机制决定的。 (pyim-dcache-get py-str pyim-dcache-code2word))) (when (member string words-from-dicts) (push pinyin-list pinyins-list-adjusted)))) (setq pinyins-list-adjusted (nreverse pinyins-list-adjusted))) ;; 返回拼音字符串或者拼音列表 (let* ((pinyins-list (or pinyins-list-adjusted pinyins-list-permutated)) (list (mapcar #'(lambda (x) (mapconcat #'(lambda (str) (if shou-zi-mu (substring str 0 1) str)) x separator)) (if ignore-duo-yin-zi (list (car pinyins-list)) pinyins-list)))) (if return-list list (mapconcat #'identity list " "))))))
(defun pyim-permutate-list (list) "使用排列组合的方式重新排列 `list',这个函数由 ‘二中’ 提供。 注:`pyim-hanzi2pinyin' 没有使用这个函数(速度稍微有点慢)。" (let ((list-head (car list)) (list-tail (cdr list))) (cond ((null list-tail) (cl-loop for element0 in list-head append (cons (cons element0 nil) nil))) (t (cl-loop for element in list-head append (mapcar (lambda (l) (cons element l)) (pyim-permutate-list list-tail)))))))
(defun pyim-permutate-list2 (list) "使用排列组合的方式重新排列 `list',这个函数由 ’翀/ty‘ 提供。 `pyim-hanzi2pinyin' 默认使用这个函数。" (if (= (length list) 1) (mapcar #'list (car list)) (pyim-permutate-list2-internal (car list) (cdr list))))
(defun pyim-permutate-list2-internal (one two) "`pyim-permutate-list2' 的内部函数。" (let (return) (if (null (car two)) one (dolist (x1 one) (dolist (x2 (car two)) (push (if (listp x1) (append x1 (list x2)) (list x1 x2)) return))) (setq one return) (pyim-permutate-list2-internal one (cdr two)))))
(defun pyim-hanzi2pinyin-simple (string &optional shou-zi-mu separator return-list) "简化版的 `pyim-hanzi2pinyin', 不处理多音字。" (pyim-hanzi2pinyin string shou-zi-mu separator return-list t))
2.16 pyim 词库管理工具
为 pyim 添加一个简单的词库管理工具 `pyim-dicts-manager' ,可以方便的执行下列命令:
- 添加词库。
- 删除词库。
- 向上和向下移动词库。
- 保存词库设置。
- 重启输入法。
(defvar pyim-dm-buffer "*pyim-dict-manager*")
(defun pyim-dm-refresh () "Refresh the contents of the *pyim-dict-manager* buffer." (interactive) (with-current-buffer pyim-dm-buffer (let ((inhibit-read-only t) (dicts-list pyim-dicts) (format-string "%-4s %-4s %-60s\n") (face-attr '((foreground-color . "DarkOrange2") (bold . t))) (i 1)) (erase-buffer) (insert (propertize (format format-string "序号" "启用" "词库文件") 'face face-attr)) (insert (propertize (format format-string "----" "----" "----------------------------------------------------------------------\n") 'face face-attr)) (if (not pyim-dicts) (insert "拼音词库是 pyim 使用顺手与否的关键。根据经验估计: 1. 当词库词条超过100万时 (词库文件>20M),pyim 选词频率大大降低。 2. 当词库词条超过100万时,pyim 中文输入体验可以达到搜狗输入法的 80%。 想快速体验 pyim 输入法的用户, 可以使用 pyim-basedict: (require 'pyim-basedict) (pyim-basedict-enable) 喜欢折腾的用户可以从下面几个途径获得 pyim 更详细的信息。 1. 使用 `C-h v pyim-dicts' 了解 pyim 词库文件格式。 2. 了解如何导入其它输入法的词库。 1. 使用 package 管理器查看 pyim 包的简介 2. 阅读 pyim.el 文件 Commentary 3. 查看 pyim 在线 README:https://github.com/tumashu/pyim\n") (dolist (dict dicts-list) (let ((disable (plist-get dict :disable)) (file (plist-get dict :file))) (insert (propertize (format format-string i (if disable "NO" "YES") file) 'id i 'disable disable 'file file))) (setq i (1+ i)))) (insert (propertize " 操作命令:[A] 添加词库 [D] 删除词库 [P] 向上移动 [N] 向下移动 [g] 刷新页面 [s] 保存配置 [R] 重启输入法 [C-c C-c] 禁用/启用当前词库" 'face face-attr)))))
(defun pyim-dm-toggle-dict (&optional enable) "启用当前行对应的词库。" (interactive) (when (equal (buffer-name) pyim-dm-buffer) (let* ((id (get-text-property (point) 'id)) (disable (get-text-property (point) 'disable)) (dict (cl-copy-list (nth (1- id) pyim-dicts))) (disable (plist-get dict :disable)) (line (line-number-at-pos))) (setf (nth (1- id) pyim-dicts) (plist-put dict :disable (not disable))) (if (not disable) (message "禁用当前词库") (message "启用当前词库")) (pyim-dm-refresh) (goto-char (point-min)) (forward-line (- line 1)))))
(defun pyim-dm-delete-dict () "从 `pyim-dicts' 中删除当前行对应的词库信息。" (interactive) (when (equal (buffer-name) pyim-dm-buffer) (let ((id (get-text-property (point) 'id)) (file (get-text-property (point) 'file)) (line (line-number-at-pos))) (when (yes-or-no-p "确定要删除这条词库信息吗? ") (setq pyim-dicts (delq (nth (1- id) pyim-dicts) pyim-dicts)) (pyim-dm-refresh) (goto-char (point-min)) (forward-line (- line 1))))))
(defun pyim-dm-dict-position-up () "向上移动词库。" (interactive) (when (equal (buffer-name) pyim-dm-buffer) (let* ((id (get-text-property (point) 'id)) (dict1 (nth (- id 1) pyim-dicts)) (dict2 (nth (- id 2) pyim-dicts)) (length (length pyim-dicts)) (line (line-number-at-pos))) (when (> id 1) (setf (nth (- id 1) pyim-dicts) dict2) (setf (nth (- id 2) pyim-dicts) dict1) (pyim-dm-refresh) (goto-char (point-min)) (forward-line (- line 2))))))
(defun pyim-dm-dict-position-down () "向下移动词库。" (interactive) (when (equal (buffer-name) pyim-dm-buffer) (let* ((id (get-text-property (point) 'id)) (dict1 (nth (- id 1) pyim-dicts)) (dict2 (nth id pyim-dicts)) (length (length pyim-dicts)) (line (line-number-at-pos))) (when (< id length) (setf (nth (1- id) pyim-dicts) dict2) (setf (nth id pyim-dicts) dict1) (pyim-dm-refresh) (goto-char (point-min)) (forward-line line)))))
(defun pyim-dm-save-dict-info () "使用 `customize-save-variable' 函数将 `pyim-dicts' 保存到 ~/.emacs 文件中。" (interactive) ;; 将`pyim-dict'的设置保存到emacs配置文件中。 (customize-save-variable 'pyim-dicts pyim-dicts) (message "将 pyim 词库配置信息保存到 ~/.emacs 文件。"))
(defun pyim-dm-add-dict () "为 `pyim-dicts' 添加词库信息。" (interactive) (when (equal (buffer-name) pyim-dm-buffer) (let ((line (line-number-at-pos)) dict name file coding first-used dict-type) (setq name (read-from-minibuffer "请输入词库名称: ")) (setq file (read-file-name "请选择词库文件: " "~/")) (setq first-used (yes-or-no-p "是否让 pyim 优先使用词库? ")) (setq dict `(:name ,name :file ,file)) (if first-used (add-to-list 'pyim-dicts dict) (add-to-list 'pyim-dicts dict t)) (pyim-dm-refresh) (goto-char (point-min)) (forward-line (- line 1)))))
(define-derived-mode pyim-dm-mode special-mode "pyim-dicts-manager" "Major mode for managing pyim dicts" (read-only-mode) (define-key pyim-dm-mode-map (kbd "D") 'pyim-dm-delete-dict) (define-key pyim-dm-mode-map (kbd "g") 'pyim-dm-refresh) (define-key pyim-dm-mode-map (kbd "A") 'pyim-dm-add-dict) (define-key pyim-dm-mode-map (kbd "N") 'pyim-dm-dict-position-down) (define-key pyim-dm-mode-map (kbd "P") 'pyim-dm-dict-position-up) (define-key pyim-dm-mode-map (kbd "s") 'pyim-dm-save-dict-info) (define-key pyim-dm-mode-map (kbd "C-c C-c") 'pyim-dm-toggle-dict) (define-key pyim-dm-mode-map (kbd "R") 'pyim-restart))
(defun pyim-dicts-manager () "pyim 词库管理器。" (interactive) (let ((buffer (get-buffer-create pyim-dm-buffer))) (pyim-dm-refresh) (switch-to-buffer buffer) (pyim-dm-mode) (setq truncate-lines t)))
(defun pyim-extra-dicts-add-dict (new-dict) "添加 `new-dict' 到 `pyim-extra-dicts', 其中 `new-dict' 的格式为: (:name \"XXX\" :file \"/path/to/XXX.pyim\") 这个函数用于制作 elpa 格式的词库 ,不建议普通用户使用。" (let (replace result) (dolist (dict pyim-extra-dicts) (if (equal (plist-get dict :name) (plist-get new-dict :name)) (progn (push new-dict result) (setq replace t)) (push dict result))) (setq result (reverse result)) (setq pyim-extra-dicts (if replace result `(,@result ,new-dict))) (message "Add pyim dict %S to `pyim-extra-dicts'." (plist-get new-dict :name)) t))
(defun pyim-dict-name-available-p (dict-name) "查询 `pyim-dicts' 中 `:name' 为 `dict-name' 的词库信息是否存在。 这个函数主要用于词库 package。" (cl-some (lambda (x) (let ((name (plist-get x :name))) (equal name dict-name))) pyim-dicts))
(defun pyim-dict-file-available-p (dict-file) "查询 `pyim-dicts' 中 `:file' 为 `dict-file' 的词库信息是否存在。 这个函数主要用于词库 package。" (cl-some (lambda (x) (let ((file (plist-get x :file))) (equal (expand-file-name file) (expand-file-name dict-file)))) pyim-dicts))
2.17 pyim 探针程序
(require 'pyim-probe)